\n
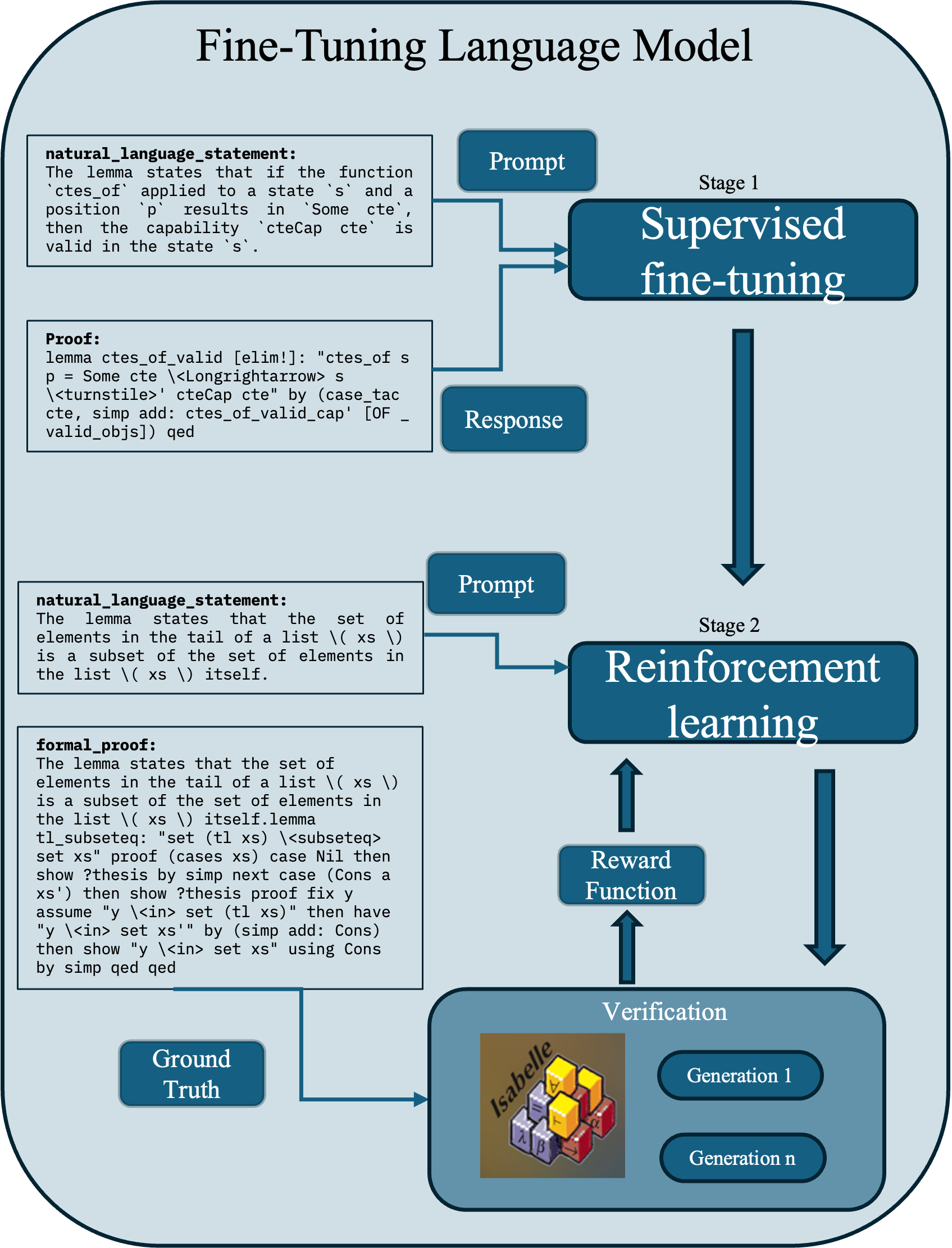
## Diagram: Fine-Tuning Language Model
### Overview
This diagram illustrates the two-stage process of fine-tuning a language model: Supervised Fine-tuning and Reinforcement Learning. It depicts the flow of information and the key components involved in each stage. The diagram is vertically oriented, with stages arranged sequentially from top to bottom.
### Components/Axes
The diagram consists of two main stages, labeled "Stage 1: Supervised fine-tuning" and "Stage 2: Reinforcement learning". Each stage includes input elements (Prompt), processing blocks, and output elements (Response/Generation). Additional components include "Ground Truth", "Reward Function", and "Verification". Text blocks containing "natural language statement" and "formal proof" are present within each stage. Arrows indicate the flow of information.
### Detailed Analysis or Content Details
**Stage 1: Supervised Fine-tuning**
* **Input:** "Prompt" is entered into the system.
* **Processing:** The prompt is processed by the "Supervised fine-tuning" block.
* **Output:** A "Response" is generated.
* **Text Block 1 (Top-Left):**
* **Title:** "natural language statement:"
* **Content:** "The lemma states that if the function `ctes_of` applied to a state `s` and a position `p` results in `Some cte`, then the capability `ctecap cte` is valid in the state `s`."
* **Text Block 2 (Bottom-Left):**
* **Title:** "Proof:"
* **Content:** "lemma ctes_of_valid [elim!]: "ctes_of s p = Some cte <longrightarrow s <turnstile> ctecAp cte" by (case-tac cte, simp add ctes_of_valid_cap) [OF _ valid_objs] qed"
**Stage 2: Reinforcement Learning**
* **Input:** "Prompt" is entered into the system.
* **Processing:** The prompt is processed by the "Reinforcement learning" block.
* **Output:** "Generation 1" and "Generation n" are generated.
* **Intermediate Components:** A "Reward Function" evaluates the generated output, and a "Verification" step is performed.
* **Text Block 3 (Top-Left):**
* **Title:** "natural language statement:"
* **Content:** "The lemma states that the set of elements in the tail of a list `(\xs \)` is a subset of the set of elements in the list `(\xs \)` itself."
* **Text Block 4 (Bottom-Left):**
* **Title:** "formal proof:"
* **Content:** "The lemma states that the set of elements in the tail of a list `(\xs \)` is a subset of the set of elements in the list `(\xs \)` itself. lemma tl_subseteq: "set (tl xs) <subseteqq set xs" proof (cases xs) case Nil then show ?thesis by simp next case (Cons a xs') then show ?thesis proof fix y assume "y <in> set (tl xs)" then have "y <in> set xs'" by (simp add: Cons) then show "y <in> set xs" using Cons by simp qed"
**Bottom Section:**
* **"Ground Truth"**: A depiction of a toy block structure (Isabelle logo visible).
* **"Generation 1"**: A depiction of a toy block structure.
* **"Generation n"**: A depiction of a toy block structure.
### Key Observations
The diagram clearly separates the two fine-tuning stages. The inclusion of both "natural language statement" and "formal proof" suggests a focus on the logical and mathematical foundations of the language model's training. The "Ground Truth" and "Generation" blocks indicate a process of comparing model outputs to a known correct answer. The progression from "Generation 1" to "Generation n" implies iterative improvement through reinforcement learning.
### Interpretation
This diagram illustrates a sophisticated approach to language model fine-tuning. The initial supervised fine-tuning stage establishes a baseline level of performance, while the subsequent reinforcement learning stage refines the model's output based on a reward signal. The inclusion of formal proofs suggests a rigorous approach to ensuring the model's logical consistency. The "Ground Truth" and "Generation" comparison highlights the iterative nature of the learning process, where the model progressively improves its ability to generate accurate and relevant responses. The diagram emphasizes the importance of both data (supervised learning) and feedback (reinforcement learning) in achieving optimal model performance. The Isabelle logo on the "Ground Truth" suggests the use of Isabelle/HOL, a formal proof assistant, in the verification process.