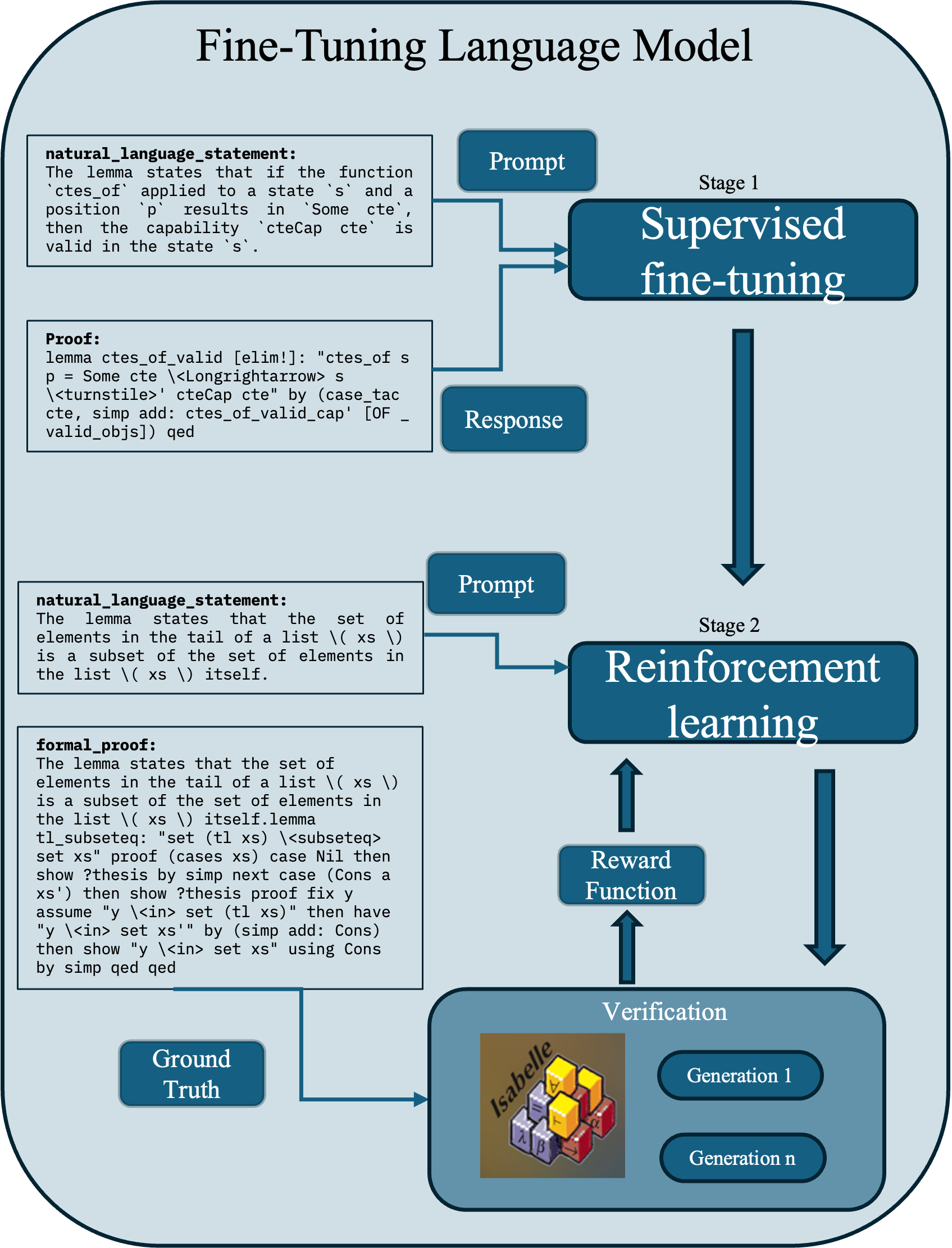
## Diagram: Fine-Tuning Language Model Pipeline
### Overview
This image is a technical flowchart illustrating a two-stage process for fine-tuning a language model, specifically for the task of generating formal mathematical proofs. The diagram details the data flow and components involved in moving from natural language statements to verified formal proofs.
### Components/Axes
The diagram is structured vertically into two main stages, with supporting components on the left and right.
**Main Title:** "Fine-Tuning Language Model" (centered at the top).
**Stage 1: Supervised fine-tuning** (Top-right, large blue box)
* **Input Components (Left side):**
* `natural_language_statement:` A text box containing: "The lemma states that if the function `ctes_of` applied to a state `s` and a position `p` results in `Some cte`, then the capability `cteCap cte` is valid in the state `s`."
* `Proof:` A text box containing formal proof code: "lemma ctes_of_valid [elim!]: \"ctes_of s p = Some cte \\<Longlongrightarrow> s \\<turnstile>' cteCap cte\" by (case_tac cte, simp add: ctes_of_valid_cap' [OF _ valid_objs]) qed"
* **Processing Components:**
* `Prompt` (Blue box): Receives input from the `natural_language_statement`.
* `Response` (Blue box): Receives input from the `Proof` box.
* Arrows from both `Prompt` and `Response` point into the `Supervised fine-tuning` block.
**Stage 2: Reinforcement learning** (Middle-right, large blue box)
* **Input Components (Left side):**
* `natural_language_statement:` A text box containing: "The lemma states that the set of elements in the tail of a list \\( xs \\) is a subset of the set of elements in the list \\( xs \\) itself."
* `formal_proof:` A text box containing a longer formal proof script: "The lemma states that the set of elements in the tail of a list \\( xs \\) is a subset of the set of elements in the list \\( xs \\) itself.lemma tl_subseteq: \"set (tl xs) \\<subseteq> set xs\" proof (cases xs) case Nil then show ?thesis by simp next case (Cons a xs') then show ?thesis proof fix y assume \"y \\<in> set (tl xs)\" then have \"y \\<in> set xs'\" by (simp add: Cons) then show \"y \\<in> set xs\" using Cons by simp qed qed"
* **Processing Components:**
* `Prompt` (Blue box): Receives input from the second `natural_language_statement`.
* An arrow from this `Prompt` points into the `Reinforcement learning` block.
* `Reward Function` (Blue box): Positioned below the `Reinforcement learning` block, with an upward-pointing arrow connecting them.
* `Verification` (Large blue box at bottom-right): Contains:
* An image of the **Isabelle** proof assistant logo (a 3D cube with Greek letters).
* Two oval buttons labeled `Generation 1` and `Generation n`.
* A downward-pointing arrow connects `Reinforcement learning` to `Verification`.
* An upward-pointing arrow connects `Verification` to the `Reward Function`.
**Supporting Component:**
* `Ground Truth` (Blue box, bottom-left): An arrow connects this box to the `Verification` block.
**Flow Arrows:** The diagram uses solid blue arrows to indicate the direction of data and process flow between all components.
### Detailed Analysis
The diagram explicitly maps the transformation of data:
1. **Stage 1 (Supervised):** Pairs of (`natural_language_statement`, `Proof`) are used as (`Prompt`, `Response`) to train the model via supervised fine-tuning.
2. **Stage 2 (Reinforcement):** The model, now presumably initialized from Stage 1, receives a new `Prompt` (from a `natural_language_statement`). It generates a `formal_proof`. This generation is sent to a `Verification` module (using the Isabelle theorem prover) which checks it against the `Ground Truth`. The result of this verification feeds into a `Reward Function`, which provides a learning signal back to the `Reinforcement learning` block, creating an iterative loop (implied by `Generation 1` to `Generation n`).
### Key Observations
* **Two Distinct Training Paradigms:** The pipeline clearly separates supervised learning (from human/correct examples) from reinforcement learning (from automated verification feedback).
* **Formal Verification is Central:** The inclusion of the Isabelle logo and the `Verification` block highlights that the ultimate goal is not just generating plausible text, but generating *correct* formal proofs that a machine can verify.
* **Iterative Refinement:** The `Generation 1` to `Generation n` labels within the Verification block suggest the reinforcement learning process involves multiple attempts or generations to produce a correct proof.
* **Ground Truth Dependency:** The `Ground Truth` feeds directly into verification, indicating the reward signal is based on comparison to a known correct proof, not just syntactic validity.
### Interpretation
This diagram outlines a sophisticated methodology for teaching a language model to perform rigorous, formal reasoning. The process leverages the strengths of different learning paradigms: supervised learning provides a strong foundational capability by learning from correct examples, while reinforcement learning with automated verification allows the model to explore, generate attempts, and improve based on objective correctness feedback. This approach is particularly valuable for domains like mathematics and software verification, where correctness is paramount and can be mechanically checked. The pipeline suggests a move beyond generating human-readable explanations towards generating machine-checkable artifacts, representing a significant step in applying large language models to formal sciences. The presence of specific Isabelle code snippets indicates this is a concrete implementation plan, not just a theoretical framework.