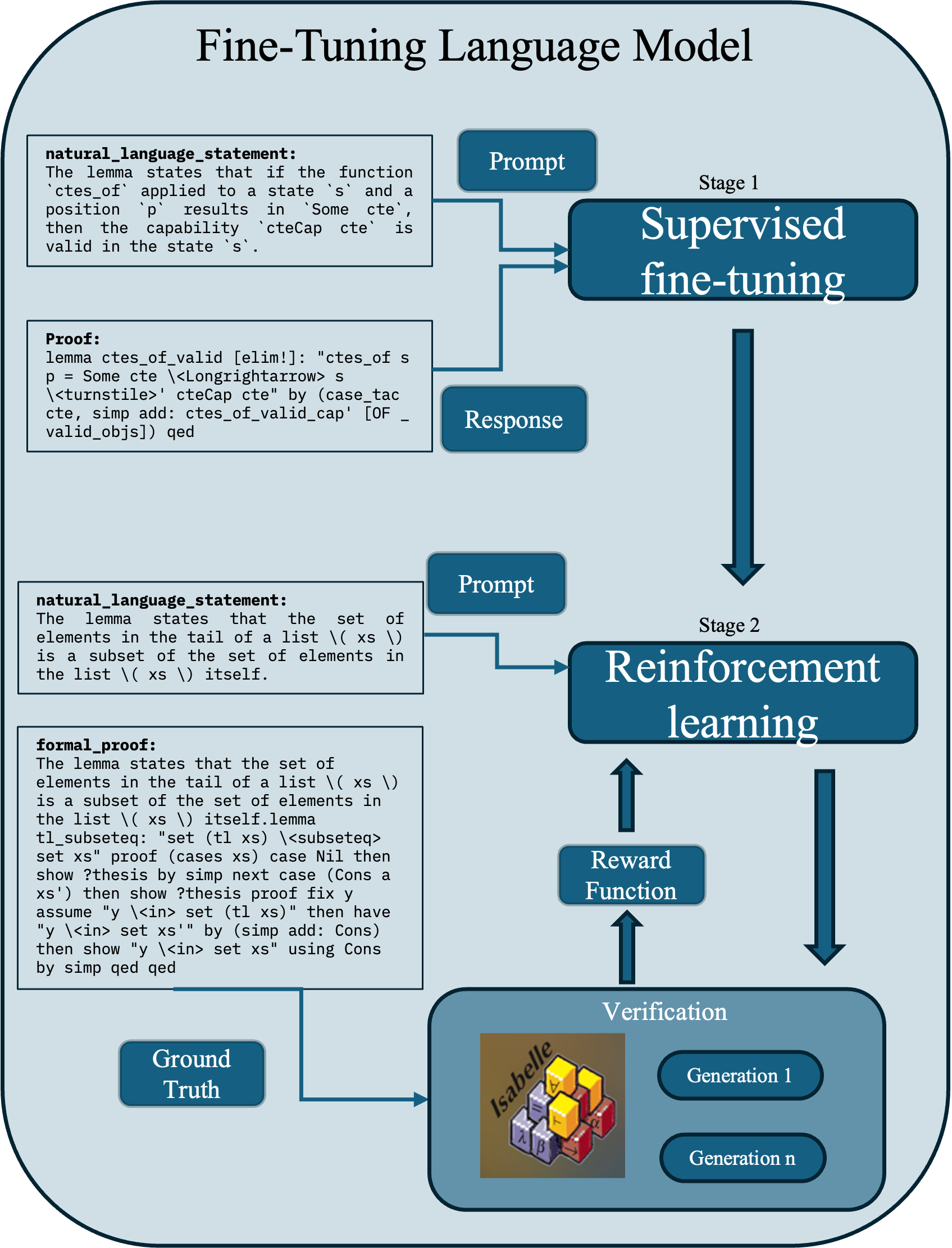
## Flowchart: Fine-Tuning Language Model
### Overview
The flowchart illustrates a two-stage process for fine-tuning a language model, combining supervised learning, reinforcement learning, and verification. It emphasizes iterative refinement through feedback loops and alignment with ground truth.
### Components/Axes
1. **Stages**:
- **Stage 1**: Supervised fine-tuning (input: natural language statement + proof; output: response).
- **Stage 2**: Reinforcement learning (input: response; output: reward function).
2. **Key Elements**:
- **Prompt**: Natural language statement or formal proof.
- **Response**: Model-generated output.
- **Reward Function**: Output of Stage 2.
- **Verification**: Cross-references responses with ground truth across generations (1 to n).
- **Ground Truth**: Reference for validation.
### Detailed Analysis
- **Stage 1 Flow**:
- A natural language statement (e.g., "If function `ctes_of` applies to state `s`...") and its formal proof are input into supervised fine-tuning.
- The model generates a response (e.g., "Lemma `ctes_of_valid`...").
- **Stage 2 Flow**:
- The response is processed through reinforcement learning, producing a reward function.
- The reward function feeds back into Stage 2, enabling iterative optimization.
- **Verification**:
- Responses are validated against ground truth (e.g., "Isabelle" theorem prover outputs).
- Generations 1 to n represent iterative model outputs refined by verification.
### Key Observations
1. **Feedback Loop**: Reinforcement learning outputs (reward function) loop back to Stage 2, enabling continuous improvement.
2. **Multi-Generation Verification**: Ground truth validation spans multiple generations, suggesting a focus on long-term model reliability.
3. **Hybrid Approach**: Combines supervised learning (Stage 1) with reinforcement learning (Stage 2) for robustness.
### Interpretation
The flowchart demonstrates a structured methodology for fine-tuning language models, prioritizing:
- **Accuracy**: Supervised fine-tuning ensures initial correctness via formal proofs.
- **Adaptability**: Reinforcement learning optimizes responses based on reward signals.
- **Reliability**: Verification against ground truth (e.g., formal theorem proofs) ensures outputs align with established knowledge.
The feedback loop between Stage 2 and verification highlights an emphasis on iterative refinement, balancing exploration (reinforcement learning) with exploitation (supervised learning). The use of formal proofs and theorem provers (e.g., Isabelle) suggests a focus on mathematical or logical domains where precision is critical.