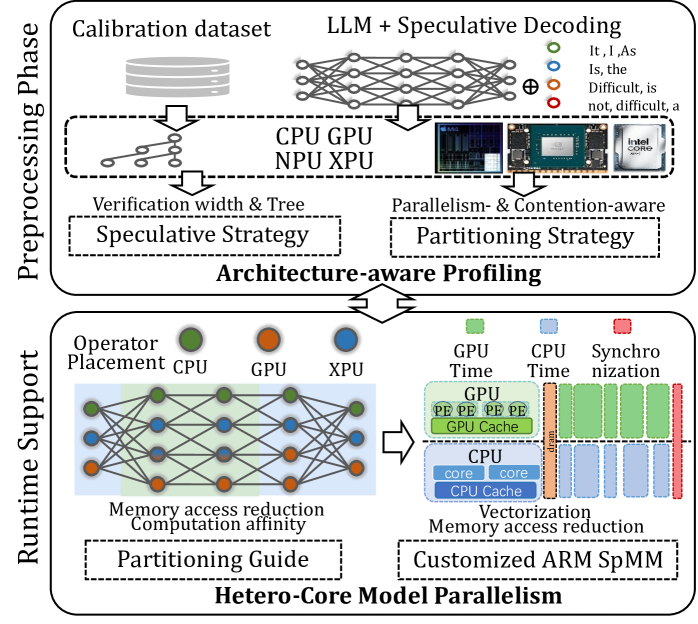
## Diagram: Hetero-Core Model Parallelism
### Overview
The image presents a diagram illustrating a hetero-core model parallelism strategy, encompassing both preprocessing and runtime support phases. It details the flow from calibration datasets and LLM speculative decoding to partitioning strategies and customized ARM SpMM.
### Components/Axes
**Preprocessing Phase (Top)**:
* **Input**: Calibration dataset (represented by stacked cylinders) and LLM + Speculative Decoding (represented by a neural network).
* Legend (top-right):
* Green circle: It, I, As
* Blue circle: Is, the
* Orange circle: Difficult, is
* Red circle: not, difficult, a
* **Processing Units**: CPU, GPU, NPU, XPU (listed below the neural network). Images of a CPU, GPU, and Intel Core chip are shown.
* **Strategies**: Verification width & Tree Speculative Strategy, and Parallelism- & Contention-aware Partitioning Strategy.
* **Central Theme**: Architecture-aware Profiling (connecting the two strategies).
**Runtime Support (Bottom)**:
* **Operator Placement**: CPU (green), GPU (orange), XPU (blue).
* **Network Representation**: A network diagram with nodes colored according to operator placement.
* **Optimization Goals**: Memory access reduction, Computation affinity.
* **Partitioning Guide**: A dashed box containing the text "Partitioning Guide".
* **Hardware Utilization**:
* GPU Time (green): Represented by stacked blocks labeled "PE" and "GPU Cache".
* CPU Time (blue): Represented by stacked blocks labeled "core" and "CPU Cache".
* Synchronization (red): Represented by stacked blocks.
* "dram" is written vertically between the CPU Time and Synchronization blocks.
* **Vectorization**: Vectorization and Memory access reduction are listed as goals.
* **Customization**: Customized ARM SpMM (Sparse Matrix-Matrix Multiplication).
* **Central Theme**: Hetero-Core Model Parallelism.
### Detailed Analysis
**Preprocessing Phase**:
1. The process begins with a "Calibration dataset" and "LLM + Speculative Decoding".
2. These inputs are processed using CPU, GPU, NPU, and XPU.
3. Two strategies are employed: "Verification width & Tree Speculative Strategy" and "Parallelism- & Contention-aware Partitioning Strategy".
4. "Architecture-aware Profiling" serves as the central theme connecting these strategies.
**Runtime Support**:
1. "Operator Placement" is visualized with green (CPU), orange (GPU), and blue (XPU) nodes in a network diagram.
2. The network diagram aims for "Memory access reduction" and "Computation affinity".
3. A "Partitioning Guide" is used.
4. Hardware utilization is shown with "GPU Time", "CPU Time", and "Synchronization" blocks.
5. "Vectorization" and "Memory access reduction" are key goals.
6. The process culminates in "Customized ARM SpMM".
### Key Observations
* The diagram illustrates a two-phase approach: Preprocessing and Runtime Support.
* Heterogeneous computing resources (CPU, GPU, NPU, XPU) are utilized.
* Optimization goals include memory access reduction, computation affinity, and vectorization.
* Partitioning strategies are central to both phases.
### Interpretation
The diagram outlines a comprehensive approach to hetero-core model parallelism. The preprocessing phase focuses on profiling and partitioning, while the runtime support phase focuses on operator placement, memory access reduction, and efficient hardware utilization. The use of speculative decoding and customized ARM SpMM suggests an emphasis on performance optimization for specific hardware architectures. The diagram highlights the importance of architecture-aware profiling and partitioning strategies in achieving efficient model parallelism across heterogeneous computing resources.