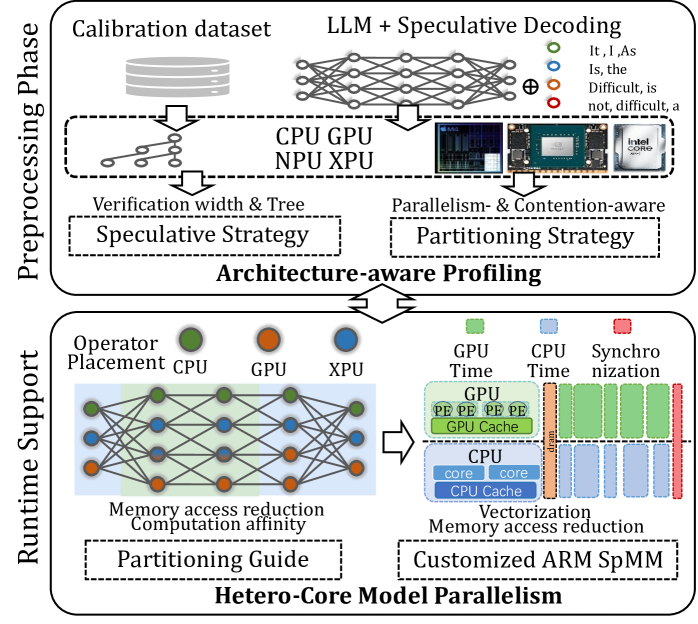
## Diagram: Architecture-aware Profiling and Hetero-Core Model Parallelism
### Overview
This diagram illustrates a two-phase process: Preprocessing Phase and Runtime Support, for architecture-aware profiling and hetero-core model parallelism. The diagram depicts data flow and component interactions involved in optimizing model execution across different processing units (CPU, GPU, NPU, XPU). It highlights the use of speculative decoding, partitioning strategies, and customized ARM SpMM for efficient model parallelism.
### Components/Axes
The diagram is divided into two main sections, vertically stacked: "Preprocessing Phase" (top) and "Runtime Support" (bottom). Each section contains several components connected by arrows indicating data flow.
* **Preprocessing Phase:**
* Calibration dataset (represented as a cylinder)
* LLM + Speculative Decoding (represented as a neural network)
* CPU, GPU, NPU, XPU (represented as rectangular blocks)
* Verification width & Tree
* Parallelism- & Contention-aware Partitioning Strategy
* Architecture-aware Profiling (central block with double-sided arrow)
* **Runtime Support:**
* Operator Placement (CPU, GPU, XPU - represented as colored circles)
* Memory access reduction Computation affinity
* Partitioning Guide
* GPU Time, CPU Time, Synchronization (represented as stacked blocks)
* Customized ARM SpMM
* Hetero-Core Model Parallelism
### Detailed Analysis or Content Details
**Preprocessing Phase:**
1. **Calibration dataset:** A cylindrical shape represents the input calibration dataset.
2. **LLM + Speculative Decoding:** A neural network diagram represents the Large Language Model (LLM) combined with speculative decoding. The network has input nodes labeled "It, I, As" and output nodes labeled "Difficult, is, not, difficult, a".
3. **Processing Units:** The diagram shows data flowing from the LLM to CPU, GPU, NPU, and XPU processing units. An Intel Core logo is present next to the CPU block.
4. **Partitioning Strategy:** The diagram indicates a "Parallelism- & Contention-aware Partitioning Strategy" and a "Speculative Strategy" are employed.
5. **Architecture-aware Profiling:** A central block labeled "Architecture-aware Profiling" connects the preprocessing phase to the runtime support phase. It has a double-sided arrow indicating bidirectional data flow.
**Runtime Support:**
1. **Operator Placement:** Three colored circles represent operator placement on CPU (green), GPU (orange), and XPU (blue).
2. **Memory Access & Affinity:** A neural network diagram represents "Memory access reduction Computation affinity".
3. **Partitioning Guide:** A rectangular block labeled "Partitioning Guide" is shown.
4. **GPU/CPU Time & Synchronization:** Stacked blocks represent GPU Time, CPU Time, and Synchronization. The GPU block shows "PE PE PE PE" repeated, and the CPU block shows "core core". A dashed line with arrows indicates synchronization between the GPU and CPU.
5. **Customized ARM SpMM:** A rectangular block labeled "Customized ARM SpMM" is shown.
6. **Hetero-Core Model Parallelism:** A rectangular block labeled "Hetero-Core Model Parallelism" is shown.
**Data Flow:**
* Data flows from the Calibration dataset to the LLM + Speculative Decoding.
* The LLM output is then distributed to the CPU, GPU, NPU, and XPU for processing.
* The Architecture-aware Profiling block acts as a bridge between the preprocessing and runtime phases.
* In the runtime phase, operators are placed on CPU, GPU, and XPU.
* Memory access is optimized, and partitioning is guided.
* GPU and CPU execution are synchronized.
* The process culminates in Hetero-Core Model Parallelism utilizing Customized ARM SpMM.
### Key Observations
* The diagram emphasizes the integration of different processing units (CPU, GPU, NPU, XPU) for model execution.
* Speculative decoding and partitioning strategies are crucial components of the preprocessing phase.
* The runtime support phase focuses on operator placement, memory access optimization, and synchronization.
* The use of Customized ARM SpMM suggests a focus on efficient matrix multiplication for model parallelism.
* The diagram is highly conceptual and does not provide specific numerical data.
### Interpretation
The diagram illustrates a system designed to optimize the execution of large language models (LLMs) by leveraging the strengths of heterogeneous computing architectures. The preprocessing phase focuses on preparing the model and identifying optimal partitioning strategies, while the runtime support phase focuses on efficient execution and synchronization across different processing units. The architecture-aware profiling component plays a critical role in bridging the gap between model preparation and runtime execution. The emphasis on memory access reduction and customized ARM SpMM suggests a focus on minimizing data movement and maximizing computational throughput. The overall goal is to achieve high performance and scalability for LLM inference by effectively utilizing the available hardware resources. The diagram suggests a holistic approach to model parallelism, considering both computational and memory aspects. The inclusion of NPU and XPU indicates a move beyond traditional CPU/GPU-centric approaches to leverage specialized hardware accelerators.