TECHNICAL ASSET FINGERPRINT
7a7df421bb75707e53fb8c79
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
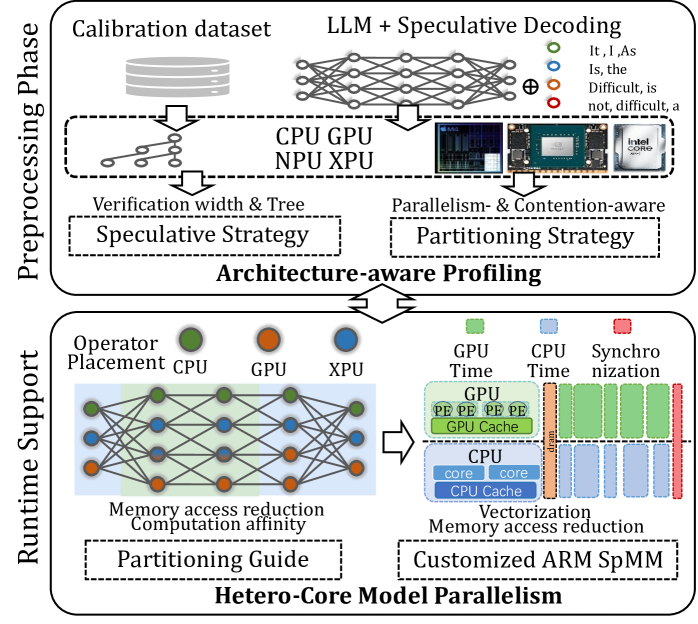
## Diagram: Hetero-Core Model Parallelism for LLM Inference
### Overview
This image is a technical system architecture diagram illustrating a two-phase approach ("Preprocessing Phase" and "Runtime Support") for optimizing Large Language Model (LLM) inference using speculative decoding across heterogeneous hardware (CPU, GPU, NPU, XPU). The goal is to achieve "Hetero-Core Model Parallelism" by making the system architecture-aware.
### Components/Axes
The diagram is vertically split into two main phases, labeled on the left side:
1. **Preprocessing Phase** (Top half)
2. **Runtime Support** (Bottom half)
**Preprocessing Phase Components:**
* **Input Data:** A "Calibration dataset" represented by a database cylinder icon.
* **Core Model:** An "LLM + Speculative Decoding" block, visualized as a neural network graph.
* **Hardware Pool:** A dashed box containing icons and labels for "CPU", "GPU", "NPU", "XPU". An Intel Core i9 processor is shown as a specific example.
* **Output Strategies:** Two dashed boxes at the bottom of this phase:
* "Speculative Strategy" (left), with the note "Verification width & Tree".
* "Partitioning Strategy" (right), with the note "Parallelism- & Contention-aware".
* **Connecting Process:** An arrow labeled "Architecture-aware Profiling" connects the Preprocessing Phase to the Runtime Support phase.
**Runtime Support Components:**
* **Operator Placement:** A legend at the top shows colored circles: Green for "CPU", Orange for "GPU", Blue for "XPU".
* **Neural Network Graph:** A large neural network diagram where nodes are colored according to the Operator Placement legend (green, orange, blue circles).
* **Optimization Goals:** Text below the network states "Memory access reduction" and "Computation affinity".
* **Output Guides:** Two dashed boxes at the bottom:
* "Partitioning Guide" (left).
* "Customized ARM SpMM" (right), with the note "Vectorization Memory access reduction".
* **Execution Timeline:** To the right of the network, a detailed timeline chart breaks down execution:
* **Legend:** Green square for "GPU Time", Blue square for "CPU Time", Red square for "Synchronization".
* **GPU Timeline:** Shows a block labeled "GPU" containing "PE PE PE PE" (Processing Elements) and "GPU Cache".
* **CPU Timeline:** Shows a block labeled "CPU" containing "core core" and "CPU Cache".
* **Synchronization:** A red vertical bar labeled "Sync" separates the GPU and CPU blocks.
* **Flow:** An arrow points from the neural network to this timeline, indicating the mapping of operators to hardware execution.
### Detailed Analysis
The diagram details a workflow for deploying LLMs efficiently:
1. **Preprocessing Phase:** A calibration dataset is fed into an LLM equipped with speculative decoding. This process is profiled across a heterogeneous hardware pool (CPU, GPU, NPU, XPU). The profiling output generates two key strategies:
* A **Speculative Strategy** that defines the "Verification width & Tree" for the speculative decoding process.
* A **Partitioning Strategy** that is "Parallelism- & Contention-aware," determining how to split the model's operations.
2. **Runtime Support:** The strategies from preprocessing guide the actual execution.
* **Operator Placement:** Individual operations (nodes in the neural network) are assigned to specific hardware (CPU, GPU, XPU) based on the partitioning guide. The colored network graph visually represents this assignment.
* **Execution Model:** The timeline illustrates the parallel execution. The GPU processes its assigned operators (PE = Processing Elements) while utilizing its cache. Concurrently, the CPU processes its assigned operators using its cores and cache. A synchronization point ("Sync") ensures coordination between the two processing streams.
* **Optimization Techniques:** The system aims for "Memory access reduction" and "Computation affinity." The "Customized ARM SpMM" (likely Sparse Matrix-Matrix multiplication) block suggests specialized kernel optimization for ARM-based CPUs to further reduce memory access via vectorization.
### Key Observations
* **Color-Coding Consistency:** The color scheme is consistent throughout: Green for CPU, Orange for GPU, Blue for XPU. This is maintained in the operator placement legend, the neural network nodes, and the execution timeline (Green for GPU Time, Blue for CPU Time).
* **Spatial Flow:** The diagram flows logically from top (preprocessing/analysis) to bottom (runtime execution), with a clear central arrow ("Architecture-aware Profiling") connecting the two phases.
* **Focus on Heterogeneity:** The system explicitly accounts for different hardware types (CPU, GPU, NPU, XPU, ARM) and their specific characteristics (caches, cores, PEs).
* **Speculative Decoding Integration:** The LLM block is specifically labeled as using "Speculative Decoding," indicating this is a core technique being optimized.
### Interpretation
This diagram presents a comprehensive framework for **co-designing LLM inference software with heterogeneous hardware architecture**. The core insight is that optimal performance cannot be achieved by treating hardware as a black box.
* **The Problem it Solves:** Running large LLMs is computationally expensive. Speculative decoding speeds up inference but adds complexity. Simply parallelizing this across different chips (CPU, GPU, etc.) is inefficient due to mismatched capabilities and contention for resources.
* **The Proposed Solution:** A two-stage, architecture-aware approach.
1. **Profiling Stage:** First, analyze the model and speculative decoding behavior on the *specific* hardware mix to create tailored strategies for speculation and operation partitioning.
2. **Execution Stage:** Use these strategies to place operators on the most suitable hardware and execute them in a coordinated, parallel manner, with custom kernels (like ARM SpMM) to minimize bottlenecks like memory access.
* **Why it Matters:** This approach moves beyond generic parallelization. It acknowledges that a CPU core, a GPU streaming multiprocessor, and an NPU have fundamentally different strengths. By making the partitioning and speculative verification "contention-aware," the system aims to maximize utilization of all available compute resources while minimizing idle time and data movement overhead, leading to faster and more efficient LLM inference. The inclusion of "NPU" and "XPU" suggests a forward-looking design for emerging AI accelerator hardware.
DECODING INTELLIGENCE...