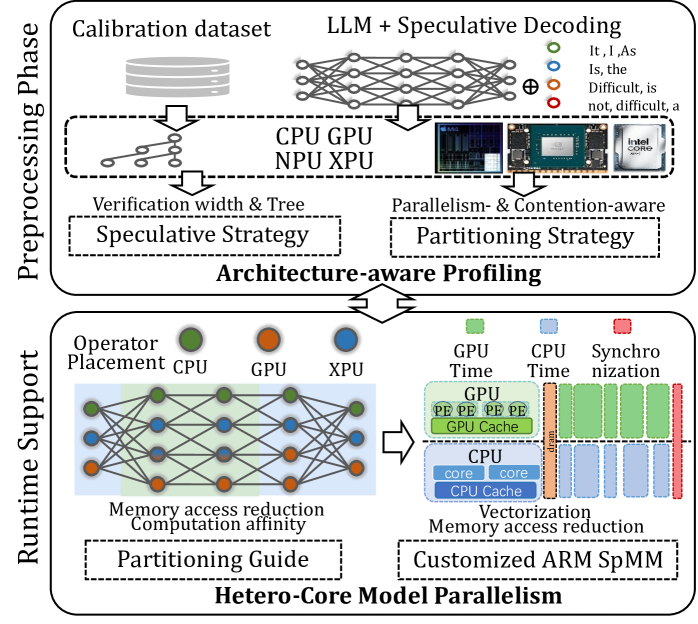
## Diagram: Hetero-Core Model Parallelism Architecture
### Overview
The diagram illustrates a two-phase system architecture for optimizing machine learning model execution. It is divided into **Preprocessing Phase** (top) and **Runtime Support** (bottom), connected by bidirectional arrows indicating workflow dependencies. The system emphasizes hardware-aware optimization strategies, memory management, and parallelism across heterogeneous compute units (CPU, GPU, NPU, XPU).
---
### Components/Axes
#### Preprocessing Phase (Top Section)
- **Calibration dataset**: Input data for model tuning.
- **LLM + Speculative Decoding**: Core processing unit with speculative execution.
- **Hardware Accelerators**:
- CPU (green), GPU (orange), NPU (blue), XPU (orange) labeled in legend.
- **Strategies**:
- *Speculative Strategy*: Linked to verification width and tree structures.
- *Partitioning Strategy*: Connected to parallelism and contention-aware optimizations.
- **Output**: Feeds into **Architecture-aware Profiling**.
#### Runtime Support (Bottom Section)
- **Operator Placement**: Allocation of tasks to hardware units.
- **Memory Access Reduction**: Techniques to minimize latency.
- **Computation Affinity**: Optimization of task-hardware alignment.
- **Partitioning Guide**: Directs task distribution.
- **Hardware-Specific Optimizations**:
- GPU Time, CPU Time, Synchro Time (timing metrics).
- GPU Cache, CPU Cache (memory hierarchies).
- **Customized ARM SpMM**: Specialized matrix multiplication for ARM architectures.
#### Legends
- **Color Coding**:
- Green: CPU
- Orange: GPU/XPU
- Blue: NPU
- Positioned in the top-right corner, adjacent to hardware accelerator labels.
---
### Detailed Analysis
1. **Preprocessing Flow**:
- The calibration dataset initializes the LLM + Speculative Decoding pipeline.
- Hardware accelerators (CPU, GPU, NPU, XPU) are integrated into the speculative decoding process.
- *Speculative Strategy* and *Partitioning Strategy* are visually linked to parallelism and contention-aware optimizations, suggesting dynamic resource allocation.
2. **Runtime Flow**:
- **Operator Placement** determines task distribution across hardware units, guided by *Partitioning Guide*.
- *Memory Access Reduction* and *Computation Affinity* are central to minimizing latency.
- Hardware-specific metrics (GPU Time, CPU Time) and caches are depicted as parallel tracks, indicating concurrent optimization.
3. **Interconnections**:
- Arrows show bidirectional flow between preprocessing and runtime, emphasizing iterative optimization.
- *Customized ARM SpMM* in the runtime section suggests ARM-specific optimizations for matrix operations.
---
### Key Observations
- **Hardware Heterogeneity**: Explicit use of CPU, GPU, NPU, and XPU indicates a focus on multi-accelerator systems.
- **Speculative Execution**: Central to preprocessing, implying probabilistic or adaptive computation.
- **Memory-Centric Optimizations**: Repeated emphasis on cache hierarchies and access reduction.
- **ARM Specialization**: The *Customized ARM SpMM* block highlights ARM architecture targeting.
---
### Interpretation
This diagram represents a **heterogeneous computing framework** for machine learning workloads, optimized for performance and efficiency. Key insights:
1. **Preprocessing-Driven Optimization**: The calibration dataset and speculative decoding suggest adaptive model tuning before runtime.
2. **Hardware-Aware Scheduling**: The *Partitioning Guide* and *Operator Placement* indicate dynamic task allocation based on hardware capabilities.
3. **Memory Efficiency**: Repeated focus on cache hierarchies and access reduction implies memory bottlenecks are a critical concern.
4. **ARM-Centric Design**: The *Customized ARM SpMM* block suggests the system is tailored for ARM-based edge or mobile devices.
The architecture balances speculative computation (for model accuracy) with hardware-aware runtime optimizations (for speed and efficiency), likely targeting real-time or resource-constrained environments.