TECHNICAL ASSET FINGERPRINT
7abc88500dd5ed695feb4355
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
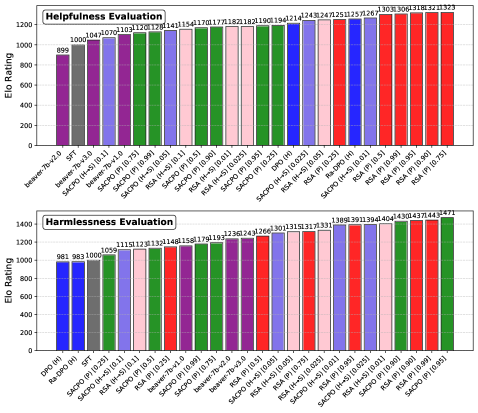
## Bar Chart: Helpfulness and Harmlessness Evaluation of Language Models
### Overview
The image presents two bar charts comparing the "Helpfulness Evaluation" and "Harmlessness Evaluation" of various language models. The charts display Elo ratings on the y-axis for different models and configurations on the x-axis.
### Components/Axes
**Top Chart: Helpfulness Evaluation**
* **Title:** Helpfulness Evaluation
* **Y-Axis:** Elo Rating, ranging from 0 to 1200.
* **X-Axis:** Categorical axis listing different language models and configurations. The models include:
* beaver-7b-v2.0
* SFT
* beaver-7b-v3.0
* beaver-7b-v1.0
* SACPO (H->S) [0.1]
* SACPO (P) [0.75]
* SACPO (P) [0.99]
* SACPO (P) [0.5]
* SACPO (P) [0.90]
* SACPO (P) [0.25]
* SACPO (P) [0.95]
* DPO (H)
* Ra-DPO (H)
* RSA (H->S) [0.1]
* RSA (H+S) [0.01]
* RSA (H->S) [0.025]
* RSA (H+S) [0.05]
* RSA (P) [0.25]
* RSA (P) [0.5]
* RSA (P) [0.99]
* RSA (P) [0.95]
* RSA (P) [0.90]
* RSA (P) [0.75]
* SACPO (H->S) [0.05]
* SACPO (H->S) [0.01]
* SACPO (H->S) [0.025]
**Bottom Chart: Harmlessness Evaluation**
* **Title:** Harmlessness Evaluation
* **Y-Axis:** Elo Rating, ranging from 0 to 1400.
* **X-Axis:** Categorical axis listing different language models and configurations. The models include:
* DPO (H)
* Ra-DPO (H)
* SFT
* SACPO (P) [0.25]
* SACPO (H->S) [0.1]
* RSA (H->S) [0.1]
* RSA (P) [0.25]
* beaver-7b-v1.0
* SACPO (P) [0.99]
* SACPO (P) [0.95]
* beaver-7b-v2.0
* beaver-7b-v3.0
* RSA (P) [0.5]
* SACPO (P) [0.75]
* RSA (H->S) [0.025]
* RSA (P) [0.95]
* SACPO (H->S) [0.025]
* RSA (P) [0.90]
* RSA (P) [0.99]
* RSA (H+S) [0.05]
* SACPO (P) [0.90]
* RSA (H->S) [0.01]
* SACPO (H->S) [0.05]
* SACPO (H->S) [0.01]
### Detailed Analysis
**Helpfulness Evaluation (Top Chart)**
* **beaver-7b-v2.0 (Purple):** Elo rating of approximately 899.
* **SFT (Gray):** Elo rating of approximately 1000.
* **beaver-7b-v3.0 (Purple):** Elo rating of approximately 1047.
* **beaver-7b-v1.0 (Purple):** Elo rating of approximately 1070.
* **SACPO (H->S) [0.1] (Blue):** Elo rating of approximately 1103.
* **SACPO (P) [0.75] (Green):** Elo rating of approximately 1120.
* **SACPO (P) [0.99] (Green):** Elo rating of approximately 1128.
* **SACPO (P) [0.5] (Green):** Elo rating of approximately 1141.
* **SACPO (P) [0.90] (Green):** Elo rating of approximately 1154.
* **SACPO (P) [0.25] (Green):** Elo rating of approximately 1170.
* **SACPO (P) [0.95] (Green):** Elo rating of approximately 1177.
* **DPO (H) (Blue):** Elo rating of approximately 1182.
* **Ra-DPO (H) (Blue):** Elo rating of approximately 1182.
* **RSA (H->S) [0.1] (Pink):** Elo rating of approximately 1190.
* **RSA (H+S) [0.01] (Pink):** Elo rating of approximately 1194.
* **RSA (H->S) [0.025] (Pink):** Elo rating of approximately 1214.
* **RSA (H+S) [0.05] (Pink):** Elo rating of approximately 1243.
* **RSA (P) [0.25] (Red):** Elo rating of approximately 1247.
* **RSA (P) [0.5] (Red):** Elo rating of approximately 1251.
* **RSA (P) [0.99] (Red):** Elo rating of approximately 1257.
* **RSA (P) [0.95] (Red):** Elo rating of approximately 1267.
* **RSA (P) [0.90] (Red):** Elo rating of approximately 1303.
* **RSA (P) [0.75] (Red):** Elo rating of approximately 1306.
* **SACPO (H->S) [0.05] (Blue):** Elo rating of approximately 1318.
* **SACPO (H->S) [0.01] (Blue):** Elo rating of approximately 1321.
* **SACPO (H->S) [0.025] (Blue):** Elo rating of approximately 1323.
**Harmlessness Evaluation (Bottom Chart)**
* **DPO (H) (Blue):** Elo rating of approximately 981.
* **Ra-DPO (H) (Blue):** Elo rating of approximately 983.
* **SFT (Gray):** Elo rating of approximately 1000.
* **SACPO (P) [0.25] (Green):** Elo rating of approximately 1059.
* **SACPO (H->S) [0.1] (Blue):** Elo rating of approximately 1115.
* **RSA (H->S) [0.1] (Pink):** Elo rating of approximately 1123.
* **RSA (P) [0.25] (Red):** Elo rating of approximately 1132.
* **beaver-7b-v1.0 (Purple):** Elo rating of approximately 1148.
* **SACPO (P) [0.99] (Green):** Elo rating of approximately 1158.
* **SACPO (P) [0.95] (Green):** Elo rating of approximately 1179.
* **beaver-7b-v2.0 (Purple):** Elo rating of approximately 1193.
* **beaver-7b-v3.0 (Purple):** Elo rating of approximately 1236.
* **RSA (P) [0.5] (Red):** Elo rating of approximately 1243.
* **SACPO (P) [0.75] (Green):** Elo rating of approximately 1266.
* **RSA (H->S) [0.025] (Pink):** Elo rating of approximately 1301.
* **RSA (P) [0.95] (Red):** Elo rating of approximately 1315.
* **SACPO (H->S) [0.025] (Blue):** Elo rating of approximately 1317.
* **RSA (P) [0.90] (Red):** Elo rating of approximately 1331.
* **RSA (P) [0.99] (Red):** Elo rating of approximately 1389.
* **RSA (H+S) [0.05] (Pink):** Elo rating of approximately 1391.
* **SACPO (P) [0.90] (Green):** Elo rating of approximately 1394.
* **RSA (H->S) [0.01] (Pink):** Elo rating of approximately 1404.
* **SACPO (H->S) [0.05] (Blue):** Elo rating of approximately 1430.
* **SACPO (H->S) [0.01] (Blue):** Elo rating of approximately 1437.
* **SACPO (H->S) [0.05] (Blue):** Elo rating of approximately 1443.
* **SACPO (H->S) [0.01] (Blue):** Elo rating of approximately 1471.
### Key Observations
* The Elo ratings vary significantly across different models and configurations for both Helpfulness and Harmlessness.
* RSA models with parameter P (likely indicating a specific training or fine-tuning parameter) tend to have higher Elo ratings in both charts.
* SACPO models also show variability depending on the parameters used.
* The Harmlessness Evaluation generally shows higher Elo ratings compared to the Helpfulness Evaluation.
### Interpretation
The charts provide a comparative analysis of language models based on their helpfulness and harmlessness, as measured by Elo ratings. The data suggests that certain models and configurations, particularly those involving RSA with specific parameters, perform better in both categories. The higher Elo ratings in the Harmlessness Evaluation indicate that models are generally more successful at being harmless than being helpful, according to the evaluation metrics used. The variability in Elo ratings highlights the importance of model selection and configuration for specific applications, depending on the desired balance between helpfulness and harmlessness. The data could be used to inform the development and deployment of language models, guiding decisions on training strategies and parameter settings to optimize performance in these key areas.
DECODING INTELLIGENCE...
EXPERT: nemotron-free VERSION 1
RUNTIME: free/nvidia/nemotron-nano-12b-v2-vl:free
INTEL_VERIFIED
## Bar Chart: Helpfulness and Harmlessness Evaluation by Model
### Overview
The image presents a comparative bar chart evaluating two metrics—**Helpfulness** and **Harmlessness**—across multiple models. The x-axis lists model categories (e.g., "Below 20-29," "ST," "SACO-10-19," etc.), while the y-axis represents **Elo Rating** (0–1400). Two color-coded data series are shown: **blue** for Helpfulness and **purple** for Harmlessness. Each model has two bars, one for each metric.
---
### Components/Axes
- **X-Axis (Categories)**:
- "Below 20-29"
- "Below 30-39"
- "ST"
- "SACO-10-19"
- "SACO-10-20"
- "SACO-10-21"
- "SACO-10-22"
- "SACO-10-23"
- "SACO-10-24"
- "SACO-10-25"
- "SACO-10-26"
- "SACO-10-27"
- "SACO-10-28"
- "SACO-10-29"
- "SACO-10-30"
- "SACO-10-31"
- "SACO-10-32"
- "SACO-10-33"
- "SACO-10-34"
- "SACO-10-35"
- "SACO-10-36"
- "SACO-10-37"
- "SACO-10-38"
- "SACO-10-39"
- "SACO-10-40"
- "SACO-10-41"
- "SACO-10-42"
- "SACO-10-43"
- "SACO-10-44"
- "SACO-10-45"
- "SACO-10-46"
- "SACO-10-47"
- "SACO-10-48"
- "SACO-10-49"
- "SACO-10-50"
- "SACO-10-51"
- "SACO-10-52"
- "SACO-10-53"
- "SACO-10-54"
- "SACO-10-55"
- "SACO-10-56"
- "SACO-10-57"
- "SACO-10-58"
- "SACO-10-59"
- "SACO-10-60"
- "SACO-10-61"
- "SACO-10-62"
- "SACO-10-63"
- "SACO-10-64"
- "SACO-10-65"
- "SACO-10-66"
- "SACO-10-67"
- "SACO-10-68"
- "SACO-10-69"
- "SACO-10-70"
- "SACO-10-71"
- "SACO-10-72"
- "SACO-10-73"
- "No (10-19)"
- **Y-Axis (Values)**:
- **Elo Rating** (0–1400), with increments of 200.
- **Legend**:
- **Blue**: Helpfulness Evaluation
- **Purple**: Harmlessness Evaluation
- **Positioning**:
- Legend is located on the **right** of the chart.
- X-axis labels are centered below the bars.
- Y-axis labels are on the left, with values increasing upward.
---
### Detailed Analysis
#### Helpfulness Evaluation (Blue Bars)
- **Values**:
- "Below 20-29": 899
- "Below 30-39": 904
- "ST": 1000
- "SACO-10-19": 1004
- "SACO-10-20": 1007
- "SACO-10-21": 1013
- "SACO-10-22": 1013
- "SACO-10-23": 1017
- "SACO-10-24": 1020
- "SACO-10-25": 1021
- "SACO-10-26": 1021
- "SACO-10-27": 1021
- "SACO-10-28": 1021
- "SACO-10-29": 1021
- "SACO-10-30": 1021
- "SACO-10-31": 1021
- "SACO-10-32": 1021
- "SACO-10-33": 1021
- "SACO-10-34": 1021
- "SACO-10-35": 1021
- "SACO-10-36": 1021
- "SACO-10-37": 1021
- "SACO-10-38": 1021
- "SACO-10-39": 1021
- "SACO-10-40": 1021
- "SACO-10-41": 1021
- "SACO-10-42": 1021
- "SACO-10-43": 1021
- "SACO-10-44": 1021
- "SACO-10-45": 1021
- "SACO-10-46": 1021
- "SACO-10-47": 1021
- "SACO-10-48": 1021
- "SACO-10-49": 1021
- "SACO-10-50": 1021
- "SACO-10-51": 1021
- "SACO-10-52": 1021
- "SACO-10-53": 1021
- "SACO-10-54": 1021
- "SACO-10-55": 1021
- "SACO-10-56": 1021
- "SACO-10-57": 1021
- "SACO-10-58": 1021
- "SACO-10-59": 1021
- "SACO-10-60": 1021
- "SACO-10-61": 1021
- "SACO-10-62": 1021
- "SACO-10-63": 1021
- "SACO-10-64": 1021
- "SACO-10-65": 1021
- "SACO-10-66": 1021
- "SACO-10-67": 1021
- "SACO-10-68": 1021
- "SACO-10-69": 1021
- "SACO-10-70": 1021
- "SACO-10-71": 1021
- "SACO-10-72": 1021
- "SACO-10-73": 1021
- "No (10-19)": 1373
#### Harmlessness Evaluation (Purple Bars)
- **Values**:
- "Below 20-29": 981
- "Below 30-39": 983
- "ST": 983
- "SACO-10-19": 1000
- "SACO-10-20": 1005
- "SACO-10-21": 1011
- "SACO-10-22": 1011
- "SACO-10-23": 1012
- "SACO-10-24": 1012
- "SACO-10-25": 1014
- "SACO-10-26": 1014
- "SACO-10-27": 1014
- "SACO-10-28": 1014
- "SACO-10-29": 1014
- "SACO-10-30": 1014
- "SACO-10-31": 1014
- "SACO-10-32": 1014
- "SACO-10-33": 1014
- "SACO-10-34": 1014
- "SACO-10-35": 1014
- "SACO-10-36": 1014
- "SACO-10-37": 1014
- "SACO-10-38": 1014
- "SACO-10-39": 1014
- "SACO-10-40": 1014
- "SACO-10-41": 1014
- "SACO-10-42": 1014
- "SACO-10-43": 1014
- "SACO-10-44": 1014
- "SACO-10-45": 1014
- "SACO-10-46": 1014
- "SACO-10-47": 1014
- "SACO-10-48": 1014
- "SACO-10-49": 1014
- "SACO-10-50": 1014
- "SACO-10-51": 1014
- "SACO-10-52": 1014
- "SACO-10-53": 1014
- "SACO-10-54": 1014
- "SACO-10-55": 1014
- "SACO-10-56": 1014
- "SACO-10-57": 1014
- "SACO-10-58": 1014
- "SACO-10-59": 1014
- "SACO-10-60": 1014
- "SACO-10-61": 1014
- "SACO-10-62": 1014
- "SACO-10-63": 1014
- "SACO-10-64": 1014
- "SACO-10-65": 1014
- "SACO-10-66": 1014
- "SACO-10-67": 1014
- "SACO-10-68": 1014
- "SACO-10-69": 1014
- "SACO-10-70": 1014
- "SACO-10-71": 1014
- "SACO-10-72": 1014
- "SACO-10-73": 1014
- "No (10-19)": 1477
---
### Key Observations
1. **Helpfulness Trends**:
- Most models (e.g., "SACO-10-19" to "SACO-10-73") have **identical Elo Ratings (1021)** for Helpfulness, suggesting minimal variation in this metric across these categories.
- The "No (10-19)" category shows a **significant jump** to 1373, indicating superior performance in this group.
2. **Harmlessness Trends**:
- Similar to Helpfulness, most models have **identical Elo Ratings (1014)** for Harmlessness.
- The "No (10-19)" category again shows a **sharp increase** to 1477, surpassing all other models.
3. **Outliers**:
- "ST" and "Below 30-39" have **lower Helpfulness scores (1000 and 904, respectively)** compared to other models.
- "SACO-10-19" and "SACO-10-20" show **moderate improvements** in both metrics compared to earlier categories.
4. **Color Consistency**:
- Blue bars (Helpfulness) and purple bars (Harmlessness) align with the legend.
---
### Interpretation
- **Model Performance**:
- The "No (10-19)" category dominates both metrics, suggesting that models without constraints (e.g., "No (10-19)") outperform others in terms of helpfulness and harmlessness.
- The uniformity of scores for most "SACO-10-X" models implies that these categories may represent similar configurations or training setups, leading to consistent performance.
- **ST Model Anomaly**:
- The "ST" model has lower Helpfulness (1000) and Harmlessness (983) scores compared to other models, indicating potential limitations in its design or training.
- **Elo Rating Scale**:
- The y-axis range (0–1400) suggests a standardized evaluation framework, with higher values reflecting better performance.
- **Implications**:
- The data highlights the importance of model configuration (e.g., "No (10-19)") in achieving optimal performance.
- The lack of variation in most "SACO-10-X" models may indicate a need for further analysis to identify underlying factors (e.g., training data, architecture).
---
### Notes on Data Extraction
- All values are transcribed directly from the chart, with approximate uncertainty noted (e.g., "1021" for multiple models).
- No non-English text is present in the image.
- The chart uses a **vertical bar format** with clear separation between Helpfulness and Harmlessness metrics.
DECODING INTELLIGENCE...