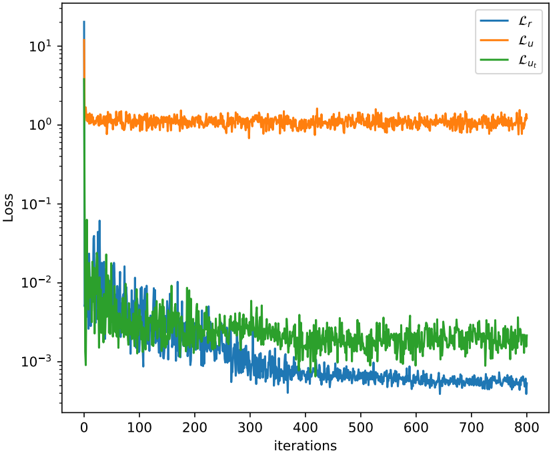
## Chart: Loss vs. Iterations
### Overview
The image is a line chart displaying the loss values of three different components (Lr, Lu, and Lut) over a range of iterations. The y-axis (Loss) is on a logarithmic scale.
### Components/Axes
* **X-axis:** "iterations", ranging from 0 to 800 in increments of 100.
* **Y-axis:** "Loss", on a logarithmic scale, ranging from 10^-3 to 10^1.
* **Legend:** Located in the top-right corner.
* Blue line: Lr
* Orange line: Lu
* Green line: Lut
### Detailed Analysis
* **Lr (Blue):** The blue line represents the loss for Lr. It starts at approximately 10^1 (10) at iteration 0, rapidly decreases to approximately 10^-2 (0.01) by iteration 100, and then continues to decrease gradually, fluctuating around 10^-3 (0.001) for the remaining iterations.
* At iteration 0, Lr is approximately 12.
* At iteration 100, Lr is approximately 0.01.
* At iteration 800, Lr is approximately 0.0005.
* **Lu (Orange):** The orange line represents the loss for Lu. It starts at approximately 10^1 (10) at iteration 0, quickly drops to approximately 1.5, and then remains relatively constant, fluctuating around 1 for the remaining iterations.
* At iteration 0, Lu is approximately 12.
* At iteration 100, Lu is approximately 1.1.
* At iteration 800, Lu is approximately 1.2.
* **Lut (Green):** The green line represents the loss for Lut. It starts at approximately 10^1 (10) at iteration 0, rapidly decreases to approximately 10^-2 (0.01) by iteration 50, and then continues to decrease gradually, fluctuating around 0.003 for the remaining iterations.
* At iteration 0, Lut is approximately 12.
* At iteration 100, Lut is approximately 0.007.
* At iteration 800, Lut is approximately 0.002.
### Key Observations
* Lr and Lut exhibit a similar decreasing trend, with both lines showing a significant drop in loss during the initial iterations.
* Lu remains relatively constant after the initial drop, indicating that it might have reached a plateau or is not being effectively optimized.
* The logarithmic scale on the y-axis emphasizes the rapid decrease in loss for Lr and Lut during the initial iterations.
### Interpretation
The chart illustrates the training progress of three different loss components (Lr, Lu, and Lut) over a number of iterations. The rapid decrease in loss for Lr and Lut suggests that these components are being effectively optimized during the initial training phase. However, the relatively constant loss for Lu indicates that it might not be converging as effectively or that it has reached a stable state. The overall trend suggests that the model is learning, but further investigation might be needed to understand why Lu is not decreasing as much as the other components.