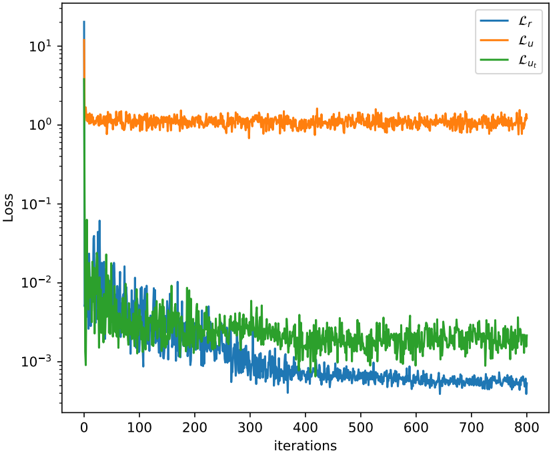
## Line Chart: Training Loss Curves Over Iterations
### Overview
The image displays a line chart plotting three different loss metrics against training iterations on a logarithmic scale. The chart visualizes the convergence behavior of what appears to be components of a machine learning model's loss function during training.
### Components/Axes
* **Chart Type:** Line chart with a logarithmic y-axis.
* **X-Axis:**
* **Label:** "iterations"
* **Scale:** Linear scale from 0 to 800.
* **Major Tick Marks:** 0, 100, 200, 300, 400, 500, 600, 700, 800.
* **Y-Axis:**
* **Label:** "Loss"
* **Scale:** Logarithmic scale (base 10).
* **Major Tick Marks (Labels):** 10⁻³, 10⁻², 10⁻¹, 10⁰, 10¹.
* **Legend:**
* **Position:** Top-right corner of the plot area.
* **Entries:**
1. **Lᵣ** (Blue line)
2. **Lᵤ** (Orange line)
3. **Lᵤₜ** (Green line)
### Detailed Analysis
The chart tracks three distinct loss series over 800 iterations.
1. **Lᵤ (Orange Line):**
* **Trend:** Starts at a very high value (≈10¹), experiences a sharp, near-vertical drop within the first few iterations, and then plateaus.
* **Values:** After the initial drop, it stabilizes and fluctuates noisily around the 10⁰ (1.0) level for the remainder of the training, showing no significant downward trend after iteration ~50.
2. **Lᵣ (Blue Line):**
* **Trend:** Begins around 10⁰, drops rapidly in the first 50-100 iterations, and then continues a steady, consistent downward trend with moderate noise.
* **Values:** It crosses below the 10⁻² mark around iteration 150 and continues to decrease, ending at the lowest value of the three series, approximately 5 x 10⁻⁴ (0.0005) by iteration 800.
3. **Lᵤₜ (Green Line):**
* **Trend:** Starts near 10⁻¹, drops quickly in the initial phase, and then enters a regime of high-variance fluctuation with a very gradual overall downward slope.
* **Values:** After the initial drop, it primarily oscillates between 10⁻³ and 10⁻². It is consistently noisier than the blue line (Lᵣ) and ends at a value higher than Lᵣ, approximately 2 x 10⁻³ (0.002).
**Spatial & Color Grounding:** The legend in the top-right correctly maps the colors: Blue to Lᵣ, Orange to Lᵤ, and Green to Lᵤₜ. The orange line (Lᵤ) is positioned highest on the chart after the initial drop. The blue line (Lᵣ) descends to become the lowest line. The green line (Lᵤₜ) remains between the other two for most of the training after the first ~100 iterations.
### Key Observations
* **Order of Magnitude Separation:** There is a clear separation of scales. Lᵤ stabilizes around 1.0, Lᵤₜ fluctuates around 0.001-0.01, and Lᵣ descends below 0.001.
* **Convergence Behavior:** Lᵤ converges (plateaus) almost immediately. Lᵣ shows continuous, stable improvement. Lᵤₜ improves initially but then exhibits high variance with minimal net improvement after the first 200 iterations.
* **Noise Profile:** Lᵤₜ (green) displays the highest variance or noise in its signal, followed by Lᵣ (blue), with Lᵤ (orange) being the smoothest after its initial convergence.
### Interpretation
This chart likely represents the decomposition of a composite loss function in a machine learning model, possibly for a task involving reconstruction (Lᵣ), an unsupervised or uncertainty component (Lᵤ), and a task-specific or uncertainty-regularized term (Lᵤₜ).
* **Lᵤ (Orange):** Its rapid convergence to a high, stable value suggests it may be a loss term that is easily minimized to a certain floor or represents a component of the model that learns very quickly but has a limited capacity for further refinement (e.g., a simple prior or a regularization term).
* **Lᵣ (Blue):** The steady, logarithmic decrease indicates this is likely the primary supervised or reconstruction loss. The model is consistently improving its core predictive or generative capability throughout training.
* **Lᵤₜ (Green):** The high noise and plateau suggest this term might be more challenging to optimize, possibly involving stochastic elements, adversarial components, or a trade-off with other losses. Its failure to decrease smoothly alongside Lᵣ could indicate a tension in the optimization landscape or that it has reached its effective minimum.
The overall picture is of a model where the main task (Lᵣ) is being learned effectively, while auxiliary components (Lᵤ, Lᵤₜ) behave differently—one converging instantly and the other struggling with stability. The logarithmic scale is crucial for visualizing the simultaneous behavior of losses operating at vastly different scales.