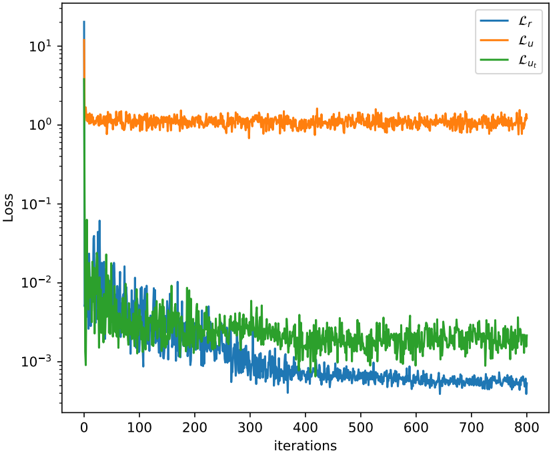
## Line Chart: Loss Metrics Over Iterations
### Overview
The chart displays three loss metrics (Lr, Lu, Lut) plotted against iterations (0–800) on a logarithmic y-axis (Loss: 10^-3 to 10^1). The blue line (Lr) shows a sharp initial decline, the orange line (Lu) remains stable at ~10^0, and the green line (Lut) decreases gradually before stabilizing.
### Components/Axes
- **X-axis**: "Iterations" (0–800, linear scale).
- **Y-axis**: "Loss" (logarithmic scale: 10^-3 to 10^1).
- **Legend**: Top-right corner, with:
- Blue: Lr
- Orange: Lu
- Green: Lut
### Detailed Analysis
1. **Lr (Blue Line)**:
- Starts at ~10^1 at iteration 0.
- Drops sharply to ~10^-3 by iteration 100.
- Stabilizes with minor fluctuations (~10^-3 to 10^-2) after iteration 100.
2. **Lu (Orange Line)**:
- Remains constant at ~10^0 (1.0) across all iterations.
- Minor noise (~10^-1 to 10^0) observed but no significant trend.
3. **Lut (Green Line)**:
- Starts at ~10^1 at iteration 0.
- Decreases to ~10^-2 by iteration 100.
- Fluctuates between ~10^-2 and 10^-1 after iteration 100.
### Key Observations
- **Lr** exhibits the most dramatic change, suggesting rapid optimization or convergence.
- **Lu**’s stability implies it may represent a baseline or unchanging loss component.
- **Lut**’s gradual decline indicates slower convergence compared to Lr.
### Interpretation
The chart likely represents a machine learning training process where:
- **Lr** (e.g., reconstruction loss) converges quickly, while **Lut** (e.g., regularization loss) decreases more slowly.
- **Lu**’s stability could indicate a fixed penalty term or a loss component unaffected by training iterations.
- The logarithmic scale emphasizes relative changes, highlighting Lr’s steep drop and Lut’s prolonged adjustment. Spikes in Lu may reflect transient events (e.g., data anomalies) or numerical noise.