\n
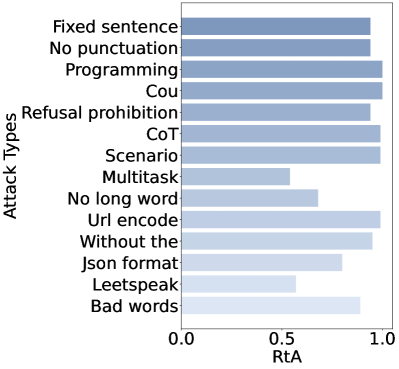
## Horizontal Bar Chart: Attack Types vs. RtA
### Overview
The image displays a horizontal bar chart comparing various "Attack Types" on the y-axis against a metric labeled "RtA" on the x-axis. The chart uses a monochromatic blue color scheme, with bars of varying lengths indicating the RtA value for each attack type. The overall visual suggests a performance or success rate comparison across different adversarial or testing methods.
### Components/Axes
* **Chart Type:** Horizontal Bar Chart.
* **Y-Axis (Vertical):** Labeled **"Attack Types"**. It lists 13 distinct categories.
* **X-Axis (Horizontal):** Labeled **"RtA"**. The scale runs from **0.0** to **1.0**, with major tick marks at 0.0, 0.5, and 1.0.
* **Legend:** There is no separate legend. The bars are colored in a gradient from a darker blue (top) to a very light blue (bottom), but this appears to be a stylistic choice rather than encoding additional categorical information.
* **Spatial Layout:** The chart occupies the central area. The y-axis labels are left-aligned. The x-axis is at the bottom. The bars extend from the y-axis to the right.
### Detailed Analysis
The following table reconstructs the data from the chart. The "RtA Value" is an approximate reading based on the bar's endpoint relative to the x-axis scale.
| Attack Type (Y-Axis Label) | Approximate RtA Value | Visual Trend / Bar Length Description |
| :--- | :--- | :--- |
| Fixed sentence | ~0.95 | Very long bar, nearly reaching 1.0. |
| No punctuation | ~0.90 | Long bar, slightly shorter than "Fixed sentence". |
| Programming | ~0.98 | Very long bar, appears to be the longest or tied for longest. |
| Cou | ~0.97 | Very long bar, similar to "Programming". |
| Refusal prohibition | ~0.90 | Long bar, similar to "No punctuation". |
| CoT | ~0.98 | Very long bar, similar to "Programming". |
| Scenario | ~0.97 | Very long bar, similar to "Cou". |
| Multitask | ~0.55 | Moderate length bar, ending just past the 0.5 mark. |
| No long word | ~0.65 | Moderate length bar, longer than "Multitask". |
| Url encode | ~0.98 | Very long bar, similar to "Programming" and "CoT". |
| Without the | ~0.95 | Very long bar, similar to "Fixed sentence". |
| Json format | ~0.80 | Long bar, but noticeably shorter than the top group. |
| Leetspeak | ~0.55 | Moderate length bar, similar to "Multitask". |
| Bad words | ~0.85 | Long bar, between "Json format" and the top group. |
### Key Observations
1. **High Performance Cluster:** A significant cluster of attack types ("Programming", "CoT", "Url encode", "Cou", "Scenario", "Fixed sentence", "Without the") all achieve RtA values at or very near 1.0. This suggests these methods are highly effective according to this metric.
2. **Mid-Range Performers:** "No punctuation", "Refusal prohibition", and "Bad words" form a middle tier with RtA values around 0.85-0.90.
3. **Lower Performance Outliers:** "Multitask" and "Leetspeak" are clear outliers on the lower end, with RtA values around 0.55. "No long word" and "Json format" also perform notably worse than the top cluster.
4. **Metric Ambiguity:** The metric "RtA" is not defined within the image. Common interpretations in AI safety/security contexts could be "Rate to Attack" (success rate), "Resistance to Attack," or similar. The high values for many attack types suggest it likely measures attack success rate.
### Interpretation
This chart appears to benchmark the effectiveness of different prompt-based or input-based "attack" strategies against a system, likely a Large Language Model (LLM). The "RtA" metric, presumably a success rate, indicates how often each attack type achieves its goal (e.g., bypassing safety filters, inducing harmful output).
The data suggests that **obfuscation and formatting-based attacks** (like "Url encode", "Json format", "Leetspeak") and **direct instruction-based attacks** (like "Fixed sentence", "Without the", "Refusal prohibition") are highly effective, with several reaching near-perfect success rates. The high performance of "CoT" (Chain-of-Thought) is particularly notable, implying that asking the model to reason step-by-step can be a powerful attack vector.
Conversely, attacks that impose **complex constraints** ("Multitask" - requiring multiple tasks, "No long word" - vocabulary restriction) or use **specific, potentially less potent obfuscation** ("Leetspeak") are significantly less effective. This could indicate that overly complex or niche attack strategies are less reliable than simpler, more direct, or broadly applicable obfuscation techniques.
The chart provides a clear hierarchy of attack efficacy, which is crucial for developers to understand which vulnerabilities are most exposed and for prioritizing defensive measures. The near-1.0 success rates for multiple attack types highlight a potential systemic weakness in the evaluated system's robustness against a variety of adversarial inputs.