TECHNICAL ASSET FINGERPRINT
7b0ead6af3178fb11d60a6bb
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
\n
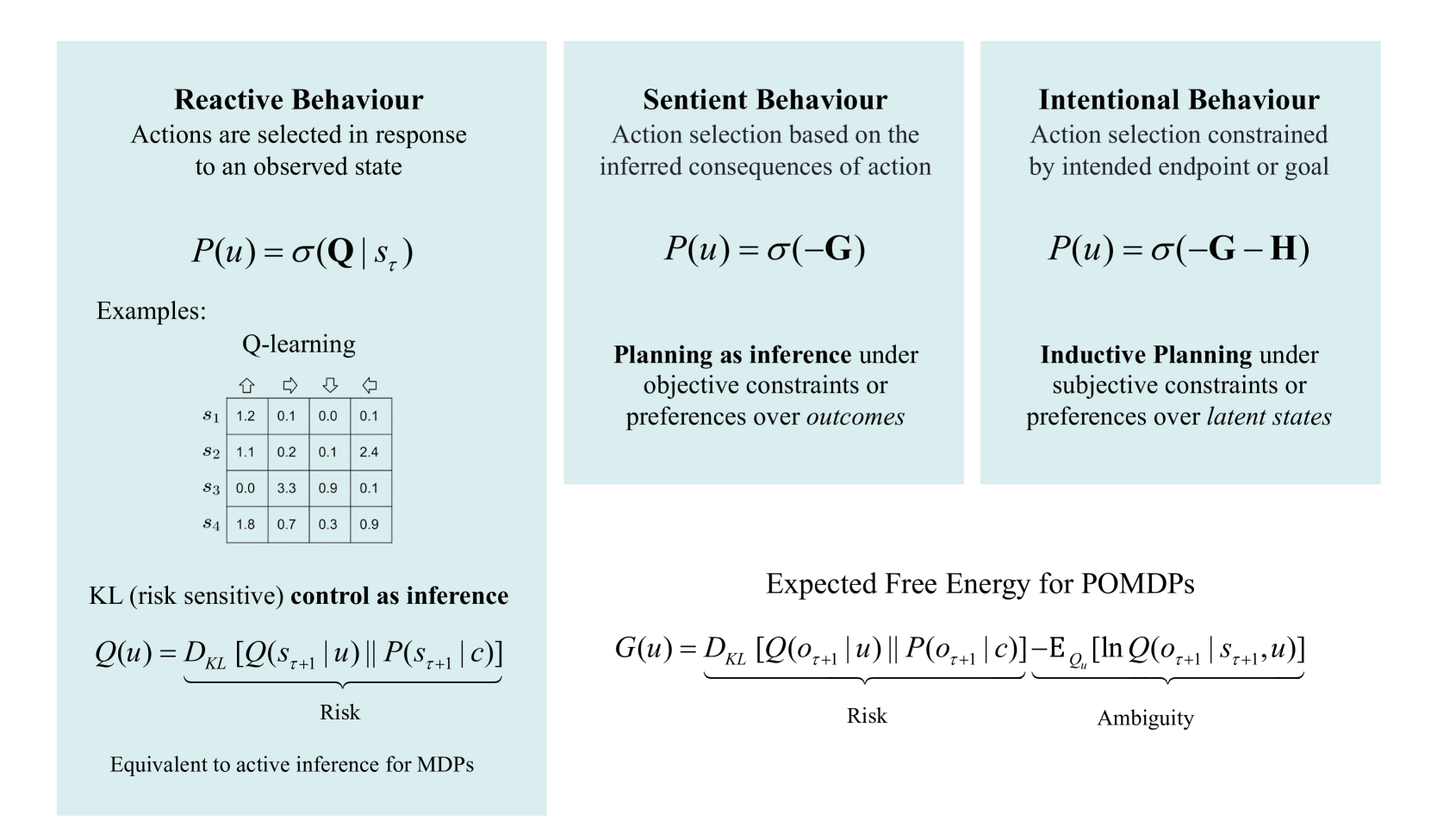
## Diagram: Comparison of Behavioural Frameworks in Active Inference
### Overview
The image is a technical diagram comparing three paradigms of action selection within the framework of active inference and control as inference: **Reactive Behaviour**, **Sentient Behaviour**, and **Intentional Behaviour**. It presents their core definitions, mathematical formulations, and associated concepts. The diagram is structured into three vertical columns for the behaviour types, with a shared foundational section at the bottom.
### Components/Axes
The diagram is organized into three primary vertical panels, each with a light blue background, and a white background section at the bottom.
**1. Left Panel: Reactive Behaviour**
* **Title:** "Reactive Behaviour"
* **Description:** "Actions are selected in response to an observed state"
* **Core Formula:** `P(u) = σ(Q | s_τ)`
* **Examples Section:** Contains a sub-section titled "Q-learning" with a 4x4 data table.
* **Additional Concept:** "KL (risk sensitive) **control as inference**" with the formula `Q(u) = D_KL [Q(s_{τ+1} | u) || P(s_{τ+1} | c)]`. The term `D_KL [...]` is underbraced and labeled "Risk".
* **Footer Note:** "Equivalent to active inference for MDPs"
**2. Middle Panel: Sentient Behaviour**
* **Title:** "Sentient Behaviour"
* **Description:** "Action selection based on the inferred consequences of action"
* **Core Formula:** `P(u) = σ(-G)`
* **Associated Concept:** "**Planning as inference** under objective constraints or preferences over *outcomes*"
**3. Right Panel: Intentional Behaviour**
* **Title:** "Intentional Behaviour"
* **Description:** "Action selection constrained by intended endpoint or goal"
* **Core Formula:** `P(u) = σ(-G - H)`
* **Associated Concept:** "**Inductive Planning** under subjective constraints or preferences over *latent states*"
**4. Bottom Section (Spanning Right Side):**
* **Title:** "Expected Free Energy for POMDPs"
* **Formula:** `G(u) = D_KL [Q(o_{τ+1} | u) || P(o_{τ+1} | c)] - E_{Q_u} [ln Q(o_{τ+1} | s_{τ+1}, u)]`
* The first term `D_KL [...]` is underbraced and labeled "Risk".
* The second term `- E_{Q_u} [...]` is underbraced and labeled "Ambiguity".
### Detailed Analysis
**Q-Learning Table (Reactive Behaviour Example):**
The table is a 4x4 matrix with rows labeled `s₁` to `s₄` (states) and columns indicated by directional arrow icons (↑, →, ↓, ←) representing actions.
| State | ↑ | → | ↓ | ← |
|-------|---|---|---|---|
| s₁ | 1.2 | 0.1 | 0.0 | 0.1 |
| s₂ | 1.1 | 0.2 | 0.1 | 2.4 |
| s₃ | 0.0 | 3.3 | 0.9 | 0.1 |
| s₄ | 1.8 | 0.7 | 0.3 | 0.9 |
These values represent Q-values (expected rewards) for taking a specific action in a given state.
**Mathematical Formulations:**
* `σ` denotes a softmax function, converting values into a probability distribution over actions `u`.
* `Q` in the Reactive formula represents the Q-value function.
* `G` represents Expected Free Energy, decomposed into Risk and Ambiguity terms in the bottom formula.
* `H` in the Intentional formula represents an additional term for subjective constraints or preferences over latent states.
* `D_KL` denotes the Kullback-Leibler divergence.
* `Q(s_{τ+1} | u)` and `P(s_{τ+1} | c)` represent posterior and prior distributions over next states, respectively.
* `Q(o_{τ+1} | u)` and `P(o_{τ+1} | c)` represent posterior and prior distributions over next observations.
* `E_{Q_u}[...]` denotes an expectation taken with respect to the distribution `Q_u`.
### Key Observations
1. **Progressive Complexity:** The three behaviour types show a clear progression in the complexity of the action selection rule: from `P(u) = σ(Q)` (Reactive), to `P(u) = σ(-G)` (Sentient), to `P(u) = σ(-G - H)` (Intentional).
2. **Unifying Framework:** All three paradigms are framed within "control as inference," where choosing an action is treated as probabilistic inference.
3. **Risk and Ambiguity:** The decomposition of Expected Free Energy (`G`) into "Risk" (divergence from preferred outcomes) and "Ambiguity" (information gain) is explicitly highlighted as foundational for planning in Partially Observable MDPs (POMDPs).
4. **Conceptual Mapping:** The diagram maps well-known algorithms to these paradigms: Q-learning is an example of Reactive Behaviour, "Planning as inference" aligns with Sentient Behaviour, and "Inductive Planning" aligns with Intentional Behaviour.
### Interpretation
This diagram serves as a conceptual taxonomy for understanding different levels of cognitive sophistication in artificial agents, grounded in the mathematics of active inference.
* **Reactive Behaviour** represents a stimulus-response mechanism. The agent acts based on cached values (`Q`) associated with the current state (`s_τ`), without explicitly simulating future consequences. The link to "KL control as inference" and "risk" suggests this can be viewed as minimizing a divergence from a desired state distribution, but in a myopic, state-conditioned way. It's equivalent to solving fully observable Markov Decision Processes (MDPs).
* **Sentient Behaviour** introduces foresight. Action selection is guided by minimizing Expected Free Energy (`G`), which involves evaluating the *inferred consequences* of actions. This corresponds to "planning as inference" where the agent infers the most likely actions to achieve preferred *outcomes* (`o`). This is suitable for partially observable environments where the agent must reason about future observations.
* **Intentional Behaviour** adds a layer of subjective preference or goal-directedness. The additional term `-H` modifies the planning objective to incorporate preferences over *latent states* (`s`), not just observable outcomes. This suggests a form of "inductive planning" where the agent has an internal model or intention (a preferred trajectory in state-space) that guides action selection beyond mere outcome preferences.
**Underlying Message:** The diagram argues that complex, goal-directed (intentional) behaviour can be derived as an extension of simpler reactive and sentient mechanisms, all within a unified probabilistic framework. The progression from Q-values to Expected Free Energy to an augmented Free Energy (`G+H`) illustrates how increasingly abstract internal models (of states, outcomes, and latent preferences) enable more sophisticated planning. The explicit breakdown of `G` into Risk and Ambiguity underscores the dual objective in active inference: achieving goals (exploitation) and reducing uncertainty (exploration).
DECODING INTELLIGENCE...