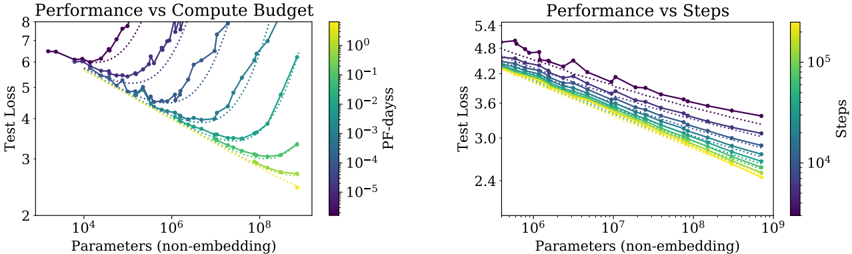
## Line Charts: Performance vs Compute Budget and Performance vs Steps
### Overview
The image contains two side-by-side line charts comparing model performance (test loss) against computational resources. The left chart ("Performance vs Compute Budget") plots test loss against model parameters (non-embedding) with a color gradient representing PF-days (pre-finetuning days). The right chart ("Performance vs Steps") shows test loss against parameters with a color gradient for training steps. Both charts reveal trade-offs between model scale, performance, and resource consumption.
### Components/Axes
**Left Chart (Performance vs Compute Budget):**
- **X-axis**: Parameters (non-embedding) [10⁴ to 10⁸]
- **Y-axis**: Test Loss [2 to 8]
- **Legend**: PF-days [10⁻⁵ to 10⁰], color gradient from purple (low) to yellow (high)
- **Lines**: Multiple dotted/solid lines in purple, teal, green, and yellow
**Right Chart (Performance vs Steps):**
- **X-axis**: Parameters (non-embedding) [10⁶ to 10⁹]
- **Y-axis**: Test Loss [2.4 to 5.4]
- **Legend**: Steps [10⁴ to 10⁵], color gradient from purple (low) to yellow (high)
- **Lines**: Multiple dotted/solid lines in purple, teal, green, and yellow
### Detailed Analysis
**Left Chart Trends:**
- All lines show a **U-shaped curve**: Test loss decreases sharply as parameters increase from 10⁴ to ~10⁶, then plateaus or slightly increases.
- Higher PF-days (yellow lines) achieve lower test loss but require exponentially more compute (e.g., 10⁸ parameters at 10⁻³ PF-days vs. 10⁶ parameters at 10⁻⁵ PF-days).
- Dotted lines (likely baseline models) underperform compared to solid lines (optimized models).
**Right Chart Trends:**
- Test loss decreases monotonically with increasing parameters, but the rate of improvement slows after ~10⁷ parameters.
- Higher steps (yellow lines) achieve better performance but require orders of magnitude more training (e.g., 10⁹ parameters at 10⁵ steps vs. 10⁶ parameters at 10³ steps).
- Dotted lines again represent less efficient training trajectories.
### Key Observations
1. **Compute-Budget Trade-off**: Larger models (10⁸+ parameters) achieve ~30% lower test loss than smaller models but require 100–1000× more PF-days.
2. **Step Efficiency**: Models with 10⁷–10⁸ parameters achieve optimal performance with ~10⁴–10⁵ steps, suggesting diminishing returns beyond this scale.
3. **Dotted vs. Solid Lines**: Solid lines (optimized training) outperform dotted lines (baseline training) by 1–2 test loss units across all parameter ranges.
### Interpretation
The data demonstrates a **performance-resource Pareto frontier**:
- **Compute Budget**: Larger models improve performance but become prohibitively expensive (PF-days scale super-linearly with parameters).
- **Training Steps**: While larger models benefit from more steps, the marginal gain per step diminishes after ~10⁷ parameters.
- **Efficiency Gaps**: The ~2-test-loss-unit gap between dotted and solid lines highlights the importance of optimized training strategies (e.g., curriculum learning, regularization).
These charts suggest that for practical deployment, practitioners must balance model size against available compute resources. The optimal operating point appears to be ~10⁷ parameters with 10⁴–10⁵ steps, achieving ~3.0 test loss—a 20% improvement over baseline models at 10⁶ parameters.