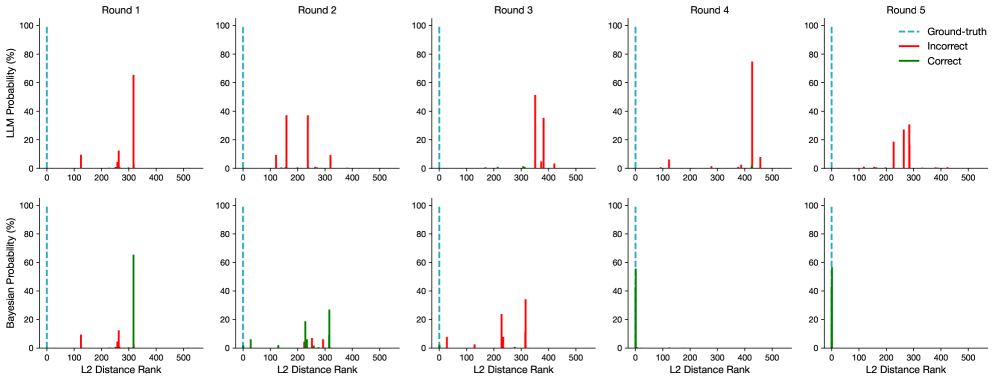
## Bar Chart: LLM and Bayesian Probability vs. L2 Distance Rank Across Rounds
### Overview
The image presents a series of bar charts comparing the probability distributions of an LLM (Large Language Model) and a Bayesian model across five rounds. The x-axis represents the L2 Distance Rank, and the y-axis represents the probability (%). Each round has two charts: the top one for the LLM and the bottom one for the Bayesian model. The charts show the distribution of "Correct" and "Incorrect" predictions, with a vertical dashed line indicating the "Ground-truth".
### Components/Axes
* **Titles:** "Round 1", "Round 2", "Round 3", "Round 4", "Round 5" (placed above each pair of charts).
* **Y-axis (Left):** "LLM Probability (%)" for the top row of charts, "Bayesian Probability (%)" for the bottom row of charts. Scale ranges from 0 to 100 in increments of 20.
* **X-axis (Bottom):** "L2 Distance Rank". Scale ranges from 0 to 500 in increments of 100.
* **Legend (Top-Right):**
* "Ground-truth" - Dashed cyan line.
* "Incorrect" - Red bars.
* "Correct" - Green bars.
### Detailed Analysis
**Round 1:**
* **LLM:** A single prominent "Incorrect" (red) bar at approximately L2 Distance Rank 350, with a probability of approximately 65%. Smaller "Incorrect" bars are present at ranks around 100 and 250, with probabilities around 10%. The "Ground-truth" line is near 0.
* **Bayesian:** A single prominent "Correct" (green) bar at approximately L2 Distance Rank 350, with a probability of approximately 70%. Small "Incorrect" (red) bars are present at ranks around 100 and 250, with probabilities around 5%. The "Ground-truth" line is near 0.
**Round 2:**
* **LLM:** Several "Incorrect" (red) bars are present between L2 Distance Ranks 100 and 300. The probabilities are approximately 50% at rank 150, 40% at rank 200, 50% at rank 250, and 20% at rank 350. The "Ground-truth" line is near 0.
* **Bayesian:** "Incorrect" (red) bars are present at ranks around 100, 200, and 250, with probabilities around 10%. "Correct" (green) bars are present at ranks around 150 and 300, with probabilities around 20%. The "Ground-truth" line is near 0.
**Round 3:**
* **LLM:** A single prominent "Incorrect" (red) bar at approximately L2 Distance Rank 350, with a probability of approximately 60%. A smaller "Incorrect" bar is present at rank around 400, with a probability around 45%. The "Ground-truth" line is near 0.
* **Bayesian:** A single prominent "Correct" (green) bar at approximately L2 Distance Rank 0, with a probability of approximately 90%. Small "Incorrect" (red) bars are present at ranks around 350 and 400, with probabilities around 10%.
**Round 4:**
* **LLM:** A single prominent "Incorrect" (red) bar at approximately L2 Distance Rank 400, with a probability of approximately 80%. The "Ground-truth" line is near 0.
* **Bayesian:** A single prominent "Correct" (green) bar at approximately L2 Distance Rank 0, with a probability of approximately 70%. A small "Incorrect" (red) bar is present at rank around 400, with a probability around 10%.
**Round 5:**
* **LLM:** Several "Incorrect" (red) bars are present between L2 Distance Ranks 200 and 350. The probabilities are approximately 20% at rank 250, 30% at rank 300, and 80% at rank 350. The "Ground-truth" line is near 0.
* **Bayesian:** A single prominent "Correct" (green) bar at approximately L2 Distance Rank 0, with a probability of approximately 60%. Small "Incorrect" (red) bars are present at ranks around 300 and 350, with probabilities around 10%.
### Key Observations
* The "Ground-truth" line consistently appears near 0 on the L2 Distance Rank axis across all rounds and models.
* The LLM tends to have higher probabilities associated with "Incorrect" predictions at higher L2 Distance Ranks.
* The Bayesian model tends to have higher probabilities associated with "Correct" predictions at lower L2 Distance Ranks, particularly at 0.
* The distribution of probabilities varies significantly between rounds for both models.
### Interpretation
The charts suggest that the Bayesian model is generally more accurate than the LLM, as it assigns higher probabilities to the correct answer (lower L2 Distance Rank) more consistently across the rounds. The LLM, on the other hand, often assigns higher probabilities to incorrect answers (higher L2 Distance Rank). The variation in probability distributions across rounds indicates that the models' performance is not consistent and may be influenced by the specific data or task in each round. The "Ground-truth" line near 0 suggests that the ideal prediction would have a very low L2 distance rank. The data highlights the strengths and weaknesses of each model, with the Bayesian model showing a tendency towards correct predictions and the LLM showing a tendency towards incorrect predictions, especially as the L2 distance rank increases.