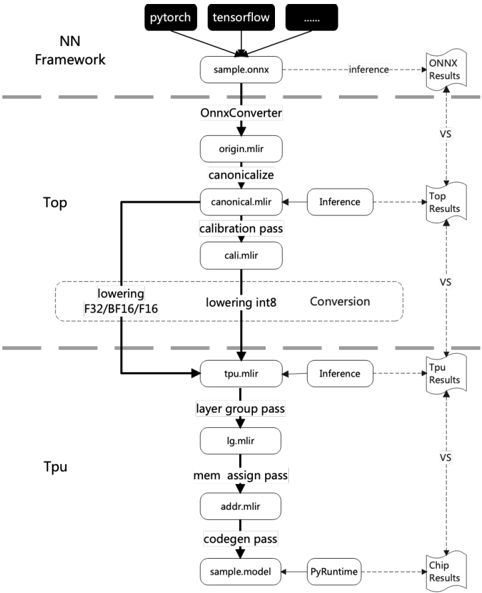
## Flowchart: Model Conversion and Inference Pipeline
### Overview
The flowchart illustrates a multi-stage pipeline for converting and optimizing machine learning models across frameworks (e.g., PyTorch, TensorFlow) and hardware (TPU). It highlights key steps in model transformation, optimization passes, and inference result comparisons between ONNX and TPU execution.
### Components/Axes
- **Top Section (NN Framework)**:
- Input: `sample.onnx` (ONNX model format).
- Frameworks: PyTorch, TensorFlow, and others.
- Key Steps:
1. **OnnxConverter**: Converts `sample.onnx` to `origin.mlir`.
2. **canonicalize**: Transforms `origin.mlir` to `canonical.mlir`.
3. **calibration pass**: Generates `cali.mlir` for quantization.
4. **lowering**: Reduces precision (F32/BF16/F16 → int8).
5. **Inference**: Executes `canonical.mlir` for ONNX Results.
- **Bottom Section (Tpu)**:
- Key Steps:
1. **lowering int8**: Further optimizes for TPU.
2. **Conversion**: Transforms `tpu.mlir` to `lg.mlir` (layer group pass).
3. **mem assign pass**: Generates `addr.mlir` for memory allocation.
4. **codegen pass**: Produces `sample.model` for PyRuntime.
5. **Inference**: Executes `tpu.mlir` for TPU Results.
- **Comparison**: "VS" arrows link ONNX Results and TPU Results to Top Results.
### Detailed Analysis
- **Flow Direction**:
- Top-to-bottom flow from framework-specific models (`sample.onnx`) to optimized TPU models (`sample.model`).
- Parallel paths for ONNX and TPU inference, converging at Top Results.
- **Critical Passes**:
- **canonicalize**: Ensures model compatibility across frameworks.
- **calibration pass**: Prepares for quantization (e.g., int8).
- **layer group pass (lg.mlir)**: Optimizes TPU-specific layer groupings.
- **mem assign pass**: Allocates memory efficiently for TPU execution.
- **Outputs**:
- **ONNX Results**: Inference output from `canonical.mlir`.
- **TPU Results**: Inference output from `tpu.mlir`.
- **Chip Results**: Final output from PyRuntime execution of `sample.model`.
### Key Observations
1. **Branching Logic**: After `canonicalize`, the pipeline splits into calibration (for ONNX) and lowering (for TPU).
2. **Precision Reduction**: Explicit lowering steps (F32 → BF16 → F16 → int8) indicate quantization for efficiency.
3. **Hardware-Specific Optimization**: TPU-specific passes (layer grouping, memory assignment) highlight hardware-aware optimizations.
4. **Result Comparison**: "VS" arrows suggest benchmarking ONNX and TPU inference performance.
### Interpretation
This flowchart represents a model optimization workflow for deploying ML models on TPUs. The process begins with framework-agnostic ONNX models, which undergo canonicalization and quantization for cross-framework compatibility. For TPU deployment, additional passes (layer grouping, memory allocation) tailor the model to TPU architecture, improving inference speed and resource utilization. The comparison of ONNX and TPU results underscores the trade-offs between framework flexibility and hardware-specific optimization. The pipeline emphasizes precision reduction (e.g., int8) and memory efficiency, critical for edge or cloud deployment. The absence of numerical data suggests the focus is on architectural flow rather than performance metrics.