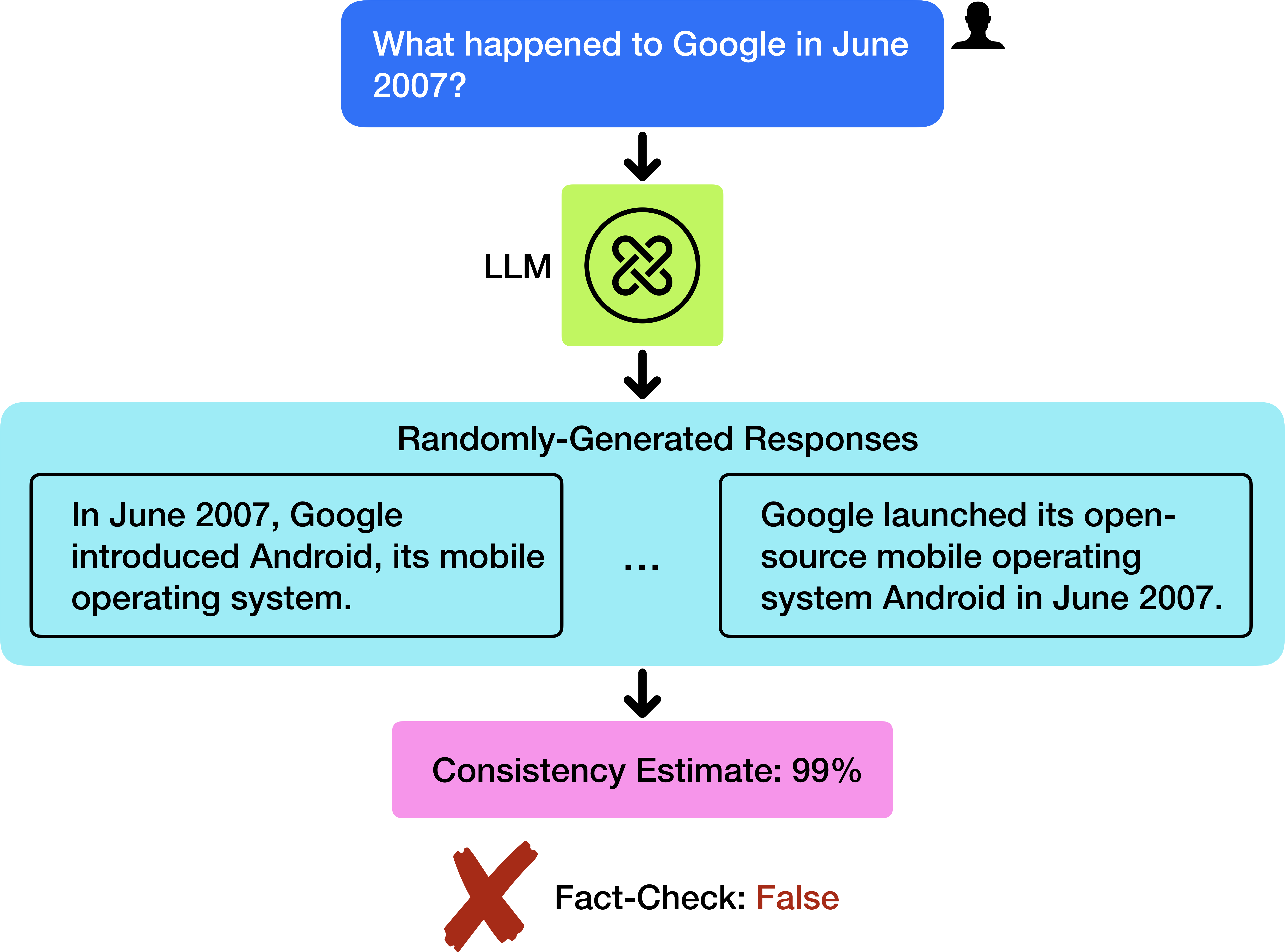
## Flowchart: LLM Response Generation and Fact-Checking Process
### Overview
The image depicts a flowchart illustrating the process of an LLM (Large Language Model) generating responses to a user query about historical events related to Google in June 2007, followed by a consistency estimate and fact-check validation.
### Components/Axes
1. **User Query**:
- Text box labeled: *"What happened to Google in June 2007?"*
- Positioned at the top of the flowchart, connected to the LLM via a downward arrow.
2. **LLM Component**:
- Green square labeled *"LLM"* with a circular logo (three interlocked lines).
- Receives input from the user query and generates responses.
3. **Randomly-Generated Responses**:
- Light blue rectangle containing two example responses:
- *"In June 2007, Google introduced Android, its mobile operating system."*
- *"Google launched its open-source mobile operating system Android in June 2007."*
- Connected to the LLM via a downward arrow.
4. **Consistency Estimate**:
- Pink rectangle labeled *"Consistency Estimate: 99%"*
- Positioned below the response examples, connected via a downward arrow.
5. **Fact-Check Validation**:
- Final section with a red "X" symbol and text:
- *"Fact-Check: False"*
- Positioned at the bottom of the flowchart.
### Detailed Analysis
- **User Query**: Explicitly asks about Google's activities in June 2007.
- **LLM Output**: Generates two nearly identical responses about Android's introduction in June 2007.
- **Consistency Estimate**: High confidence (99%) in the generated responses.
- **Fact-Check**: Explicitly marked as false, contradicting the LLM's output.
### Key Observations
1. The LLM produces responses with high internal consistency (99%) but fails fact-checking.
2. Both generated responses are factually incorrect (Android was launched in November 2007, not June).
3. The flowchart highlights a critical limitation: LLMs may generate confident but inaccurate outputs.
### Interpretation
This flowchart demonstrates a common challenge in AI systems: **confidence ≠ accuracy**. The LLM’s high consistency estimate (99%) suggests strong internal coherence in its responses, but the fact-check reveals a factual error. This underscores the need for external validation mechanisms when deploying LLMs for factual tasks. The discrepancy between the model’s confidence and the ground-truth fact-check highlights risks in relying solely on AI-generated information without verification.