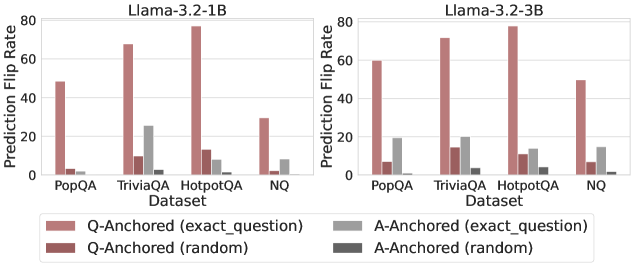
\n
## Bar Chart: Prediction Flip Rate for Llama-3.2-1B and Llama-3.2-3B
### Overview
This image presents two side-by-side bar charts comparing the Prediction Flip Rate for two language models, Llama-3.2-1B and Llama-3.2-3B, across four datasets: PopQA, TriviaQA, HotpotQA, and NQ. The flip rate is measured for both "Q-Anchored" (based on the exact question) and "A-Anchored" (based on the exact answer) prompts, with both "exact_question" and "random" variations within each anchoring method.
### Components/Axes
* **X-axis:** Dataset (PopQA, TriviaQA, HotpotQA, NQ)
* **Y-axis:** Prediction Flip Rate (ranging from 0 to 80)
* **Models:** Llama-3.2-1B (left chart), Llama-3.2-3B (right chart)
* **Legend:**
* Q-Anchored (exact_question) - Light Red
* Q-Anchored (random) - Dark Red
* A-Anchored (exact_question) - Light Gray
* A-Anchored (random) - Dark Gray
* **Title:** "Llama-3.2-1B" (above left chart), "Llama-3.2-3B" (above right chart)
* **Legend Position:** Bottom-center, spanning both charts.
### Detailed Analysis or Content Details
**Llama-3.2-1B (Left Chart)**
* **PopQA:**
* Q-Anchored (exact_question): Approximately 45
* Q-Anchored (random): Approximately 5
* A-Anchored (exact_question): Approximately 10
* A-Anchored (random): Approximately 2
* **TriviaQA:**
* Q-Anchored (exact_question): Approximately 70
* Q-Anchored (random): Approximately 10
* A-Anchored (exact_question): Approximately 25
* A-Anchored (random): Approximately 5
* **HotpotQA:**
* Q-Anchored (exact_question): Approximately 75
* Q-Anchored (random): Approximately 10
* A-Anchored (exact_question): Approximately 10
* A-Anchored (random): Approximately 2
* **NQ:**
* Q-Anchored (exact_question): Approximately 30
* Q-Anchored (random): Approximately 5
* A-Anchored (exact_question): Approximately 10
* A-Anchored (random): Approximately 2
**Llama-3.2-3B (Right Chart)**
* **PopQA:**
* Q-Anchored (exact_question): Approximately 60
* Q-Anchored (random): Approximately 10
* A-Anchored (exact_question): Approximately 20
* A-Anchored (random): Approximately 5
* **TriviaQA:**
* Q-Anchored (exact_question): Approximately 75
* Q-Anchored (random): Approximately 15
* A-Anchored (exact_question): Approximately 30
* A-Anchored (random): Approximately 10
* **HotpotQA:**
* Q-Anchored (exact_question): Approximately 80
* Q-Anchored (random): Approximately 15
* A-Anchored (exact_question): Approximately 15
* A-Anchored (random): Approximately 5
* **NQ:**
* Q-Anchored (exact_question): Approximately 50
* Q-Anchored (random): Approximately 10
* A-Anchored (exact_question): Approximately 15
* A-Anchored (random): Approximately 5
### Key Observations
* **Q-Anchored (exact_question)** consistently shows the highest flip rates across all datasets for both models.
* **A-Anchored (random)** consistently shows the lowest flip rates across all datasets for both models.
* The Llama-3.2-3B model generally exhibits higher flip rates than the Llama-3.2-1B model across all datasets and anchoring methods.
* TriviaQA and HotpotQA datasets consistently show higher flip rates than PopQA and NQ datasets.
* The difference between "exact_question" and "random" variations is more pronounced for Q-Anchored prompts than for A-Anchored prompts.
### Interpretation
The data suggests that the method of anchoring the prompt (question vs. answer) significantly impacts the prediction flip rate. Anchoring based on the question (Q-Anchored) leads to higher flip rates, especially when using the exact question. This indicates that the model is more sensitive to variations in the question phrasing. The larger model (Llama-3.2-3B) demonstrates a greater susceptibility to these variations, as evidenced by its generally higher flip rates.
The higher flip rates observed on TriviaQA and HotpotQA datasets might be attributed to the complexity of these datasets, requiring more nuanced reasoning and potentially making the model more prone to inconsistencies. The relatively low flip rates for A-Anchored (random) prompts suggest that the model is more stable when guided by the answer, regardless of the question phrasing.
The difference between "exact_question" and "random" variations highlights the importance of prompt engineering and the potential for adversarial attacks that exploit sensitivity to question phrasing. The data suggests that the models are not entirely robust to slight changes in the input question, particularly when the prompt is anchored to the question itself. This could be a vulnerability in real-world applications where user input might be noisy or intentionally manipulated.