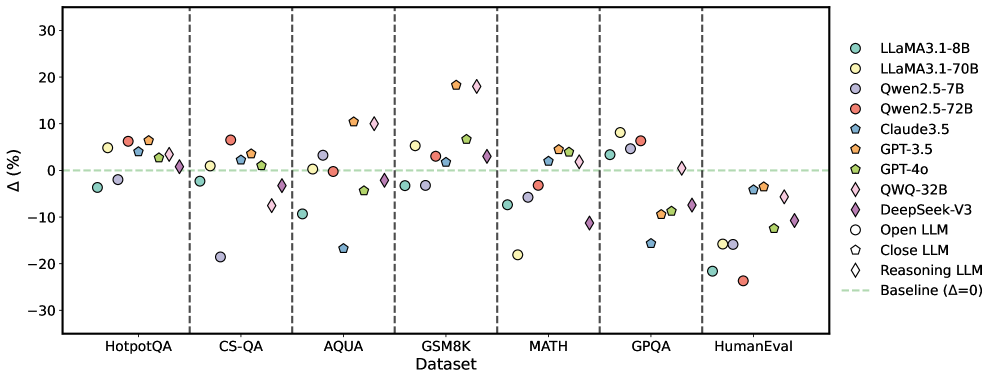
\n
## Scatter Plot: Performance Comparison of Language Models
### Overview
This image presents a scatter plot comparing the performance of various Large Language Models (LLMs) across seven different datasets. The y-axis represents the percentage difference (Δ (%)) in performance relative to a baseline, and the x-axis lists the datasets used for evaluation. Each point on the plot represents the performance of a specific LLM on a specific dataset.
### Components/Axes
* **X-axis:** Dataset - with the following categories: HotpotQA, CS-QA, AQUA, GSM8K, MATH, GPQA, HumanEval.
* **Y-axis:** Δ (%) - Percentage difference in performance. Scale ranges from approximately -30% to 30%.
* **Legend:** Located in the top-right corner, identifies each LLM with a corresponding color and marker shape. The legend includes:
* LLaMA3-1-8B (Light Blue Circle)
* LLaMA3-1-70B (Yellow Circle)
* Qwen2-5-7B (Gray Circle)
* Qwen2-5-72B (Red Circle)
* Claude3.5 (Dark Blue Triangle)
* GPT-3.5 (Orange Triangle)
* GPT-40 (Brown Diamond)
* QWQ-32B (Purple Diamond)
* DeepSeek-V3 (Magenta Diamond)
* Open LLM (White Circle)
* Close LLM (Light Gray Circle)
* Reasoning LLM (Black Diamond)
* Baseline (Δ=0) (Black Dashed Line)
### Detailed Analysis
The plot shows the performance variations of different LLMs across the seven datasets. Vertical dashed lines separate each dataset.
* **HotpotQA:** Performance varies significantly. LLaMA3-1-70B (Yellow) shows a positive difference of approximately +8%, while Qwen2-5-7B (Gray) shows a negative difference of approximately -12%.
* **CS-QA:** Generally, models perform relatively poorly. Qwen2-5-72B (Red) shows a slight positive difference of around +5%, while several models, including LLaMA3-1-8B (Light Blue) and Qwen2-5-7B (Gray), show negative differences ranging from -5% to -15%.
* **AQUA:** GPT-40 (Brown) exhibits the highest positive difference, around +18%. LLaMA3-1-8B (Light Blue) and LLaMA3-1-70B (Yellow) show moderate positive differences of approximately +5% to +10%.
* **GSM8K:** GPT-40 (Brown) again shows a strong positive difference, around +15%. Qwen2-5-72B (Red) also performs well, with a difference of approximately +8%.
* **MATH:** GPT-40 (Brown) demonstrates the highest performance, with a difference of approximately +20%. Qwen2-5-72B (Red) shows a positive difference of around +10%.
* **GPQA:** Performance is mixed. DeepSeek-V3 (Magenta) shows a positive difference of approximately +10%, while Claude3.5 (Dark Blue) shows a negative difference of around -8%.
* **HumanEval:** GPT-40 (Brown) shows a positive difference of approximately +10%. Several models, including LLaMA3-1-8B (Light Blue) and Qwen2-5-7B (Gray), show negative differences ranging from -5% to -15%.
### Key Observations
* GPT-40 consistently outperforms other models across most datasets, particularly in GSM8K, MATH, and AQUA.
* LLaMA3-1-70B generally performs better than LLaMA3-1-8B.
* Qwen2-5-72B consistently outperforms Qwen2-5-7B.
* Performance varies significantly depending on the dataset. Some models excel in specific areas (e.g., GPT-40 in reasoning tasks like GSM8K and MATH) while struggling in others.
* The baseline (Δ=0) is represented by a horizontal dashed line, providing a reference point for evaluating model performance.
### Interpretation
The data suggests that GPT-40 is currently the most capable LLM across a diverse range of tasks, particularly those requiring reasoning and mathematical abilities. The LLaMA3 models demonstrate competitive performance, with the larger 70B parameter version consistently outperforming the 8B version. The Qwen2 models also show a clear trend of improved performance with increasing parameter size. The significant variation in performance across datasets highlights the importance of evaluating LLMs on a comprehensive suite of benchmarks to understand their strengths and weaknesses. The negative differences observed for some models on certain datasets indicate that these models may not be well-suited for those specific tasks. The plot provides a valuable comparative analysis of LLM performance, enabling informed decisions about model selection for different applications. The consistent outperformance of GPT-40 suggests a significant advancement in LLM capabilities, potentially due to architectural innovations or training data quality.