TECHNICAL ASSET FINGERPRINT
7d99b7a671d3022e28249266
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
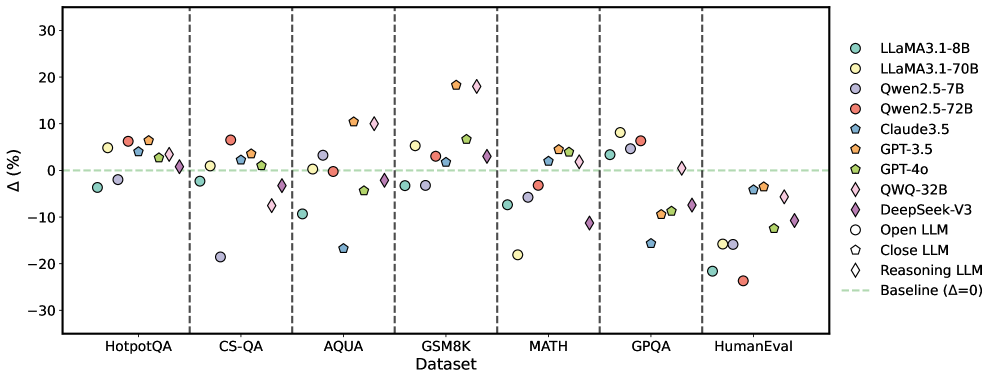
## Scatter Plot: LLM Performance Delta Across Datasets
### Overview
The image is a scatter plot (or dot plot) comparing the performance change (Δ%) of various Large Language Models (LLMs) across seven different benchmark datasets. Each model is represented by a unique colored shape, and its performance relative to a baseline (Δ=0) is plotted for each dataset. The plot is divided into vertical sections by dataset.
### Components/Axes
* **X-Axis (Horizontal):** Labeled "Dataset". It lists seven distinct benchmark categories, separated by vertical dashed lines. From left to right:
1. HotpotQA
2. CS-QA
3. AQUA
4. GSM8K
5. MATH
6. GPQA
7. HumanEval
* **Y-Axis (Vertical):** Labeled "Δ (%)". It represents the percentage change in performance. The scale ranges from -30 to +30, with major tick marks at intervals of 10 (-30, -20, -10, 0, 10, 20, 30).
* **Baseline:** A horizontal dashed green line at Δ=0, indicating no change in performance.
* **Legend:** Located on the right side of the chart. It maps symbols and colors to specific LLMs and categories:
* **Open LLMs (Circle symbols):**
* `LLaMA3.1-8B` (Teal circle)
* `LLaMA3.1-70B` (Yellow circle)
* `Qwen2.5-7B` (Light purple circle)
* `Qwen2.5-72B` (Red circle)
* **Close LLMs (Pentagon symbols):**
* `Claude3.5` (Blue pentagon)
* `GPT-3.5` (Orange pentagon)
* `GPT-4o` (Green pentagon)
* `QWQ-32B` (Light blue pentagon)
* **Reasoning LLM (Diamond symbol):**
* `DeepSeek-V3` (Purple diamond)
* **Baseline:** `Baseline (Δ=0)` (Green dashed line)
### Detailed Analysis
The following lists the approximate Δ (%) value for each model within each dataset section. Values are estimated based on the vertical position of each symbol relative to the y-axis scale.
**1. HotpotQA**
* `LLaMA3.1-8B` (Teal circle): ~ -4%
* `LLaMA3.1-70B` (Yellow circle): ~ +5%
* `Qwen2.5-7B` (Light purple circle): ~ -2%
* `Qwen2.5-72B` (Red circle): ~ +6%
* `Claude3.5` (Blue pentagon): ~ +7%
* `GPT-3.5` (Orange pentagon): ~ +5%
* `GPT-4o` (Green pentagon): ~ +7%
* `QWQ-32B` (Light blue pentagon): ~ +1%
* `DeepSeek-V3` (Purple diamond): ~ +1%
**2. CS-QA**
* `LLaMA3.1-8B` (Teal circle): ~ -2%
* `LLaMA3.1-70B` (Yellow circle): ~ +1%
* `Qwen2.5-7B` (Light purple circle): ~ -19%
* `Qwen2.5-72B` (Red circle): ~ +7%
* `Claude3.5` (Blue pentagon): ~ +3%
* `GPT-3.5` (Orange pentagon): ~ +2%
* `GPT-4o` (Green pentagon): ~ +3%
* `QWQ-32B` (Light blue pentagon): ~ -4%
* `DeepSeek-V3` (Purple diamond): ~ -8%
**3. AQUA**
* `LLaMA3.1-8B` (Teal circle): ~ -9%
* `LLaMA3.1-70B` (Yellow circle): ~ 0%
* `Qwen2.5-7B` (Light purple circle): ~ +3%
* `Qwen2.5-72B` (Red circle): ~ 0%
* `Claude3.5` (Blue pentagon): ~ -17%
* `GPT-3.5` (Orange pentagon): ~ +10%
* `GPT-4o` (Green pentagon): ~ -4%
* `QWQ-32B` (Light blue pentagon): ~ +10%
* `DeepSeek-V3` (Purple diamond): ~ +10%
**4. GSM8K**
* `LLaMA3.1-8B` (Teal circle): ~ -3%
* `LLaMA3.1-70B` (Yellow circle): ~ +5%
* `Qwen2.5-7B` (Light purple circle): ~ -3%
* `Qwen2.5-72B` (Red circle): ~ +3%
* `Claude3.5` (Blue pentagon): ~ +2%
* `GPT-3.5` (Orange pentagon): ~ +18%
* `GPT-4o` (Green pentagon): ~ +7%
* `QWQ-32B` (Light blue pentagon): ~ +3%
* `DeepSeek-V3` (Purple diamond): ~ +18%
**5. MATH**
* `LLaMA3.1-8B` (Teal circle): ~ -7%
* `LLaMA3.1-70B` (Yellow circle): ~ -18%
* `Qwen2.5-7B` (Light purple circle): ~ -6%
* `Qwen2.5-72B` (Red circle): ~ -3%
* `Claude3.5` (Blue pentagon): ~ +2%
* `GPT-3.5` (Orange pentagon): ~ +5%
* `GPT-4o` (Green pentagon): ~ +4%
* `QWQ-32B` (Light blue pentagon): ~ +2%
* `DeepSeek-V3` (Purple diamond): ~ -11%
**6. GPQA**
* `LLaMA3.1-8B` (Teal circle): ~ +3%
* `LLaMA3.1-70B` (Yellow circle): ~ +8%
* `Qwen2.5-7B` (Light purple circle): ~ +5%
* `Qwen2.5-72B` (Red circle): ~ +6%
* `Claude3.5` (Blue pentagon): ~ -16%
* `GPT-3.5` (Orange pentagon): ~ -9%
* `GPT-4o` (Green pentagon): ~ -9%
* `QWQ-32B` (Light blue pentagon): ~ -7%
* `DeepSeek-V3` (Purple diamond): ~ 0%
**7. HumanEval**
* `LLaMA3.1-8B` (Teal circle): ~ -22%
* `LLaMA3.1-70B` (Yellow circle): ~ -16%
* `Qwen2.5-7B` (Light purple circle): ~ -16%
* `Qwen2.5-72B` (Red circle): ~ -24%
* `Claude3.5` (Blue pentagon): ~ -4%
* `GPT-3.5` (Orange pentagon): ~ -4%
* `GPT-4o` (Green pentagon): ~ -12%
* `QWQ-32B` (Light blue pentagon): ~ -4%
* `DeepSeek-V3` (Purple diamond): ~ -12%
### Key Observations
1. **Dataset-Specific Performance:** Model performance is highly variable across datasets. No single model consistently outperforms others on all tasks.
2. **Strong Positive Outliers:** `GPT-3.5` and `DeepSeek-V3` show the largest positive gains on the **GSM8K** dataset (~+18%). `GPT-3.5` also performs well on **AQUA** (~+10%).
3. **Strong Negative Outliers:** The **HumanEval** dataset shows the most significant negative performance deltas across nearly all models, with `Qwen2.5-72B` showing the largest drop (~-24%). `LLaMA3.1-70B` shows a notable drop on **MATH** (~-18%).
4. **Model Category Trends:**
* **Open LLMs (Circles):** Show mixed results. `Qwen2.5-72B` (Red) is often positive but has a severe drop on HumanEval. `LLaMA3.1-70B` (Yellow) is generally positive except on MATH and HumanEval.
* **Close LLMs (Pentagons):** `GPT-3.5` (Orange) and `GPT-4o` (Green) are frequently above the baseline. `Claude3.5` (Blue) shows significant negative performance on AQUA and GPQA.
* **Reasoning LLM (Diamond):** `DeepSeek-V3` (Purple) is highly variable, with large positive gains on GSM8K and AQUA, but negative performance on CS-QA and MATH.
5. **Baseline Comparison:** The majority of data points lie above the Δ=0 baseline, suggesting that, for these specific benchmarks and this comparison metric, most models show a performance increase. The notable exception is the **HumanEval** dataset.
### Interpretation
This chart likely illustrates the performance change (Δ%) of various LLMs when subjected to a specific intervention, technique, or compared to a different baseline model, across a suite of standard benchmarks. The "Δ (%)" metric implies a relative improvement or degradation.
* **Task Specialization:** The data strongly suggests that model capabilities are not monolithic. A model excelling in mathematical reasoning (e.g., GSM8K, AQUA) may not be the best for coding (HumanEval) or complex question answering (GPQA). This highlights the importance of selecting models based on the specific task domain.
* **Impact of Scale and Type:** The comparison between different sizes of the same model family (e.g., LLaMA3.1-8B vs. 70B, Qwen2.5-7B vs. 72B) does not show a uniform "bigger is better" trend. The performance delta is context-dependent, indicating that the intervention or comparison being measured affects models of different scales in non-linear ways.
* **Coding Benchmark Challenge:** The uniformly negative performance on **HumanEval** is a critical finding. It suggests that whatever change is being measured (e.g., a new training method, quantization, a different prompting strategy) has a detrimental effect on code generation capabilities across a wide range of model architectures and sizes. This could be a significant trade-off to consider.
* **Volatility of "Reasoning" Models:** The high variance in `DeepSeek-V3`'s performance—being a top performer on some tasks and a poor performer on others—might indicate that its "reasoning" specialization makes it particularly sensitive to the conditions of the benchmark or the nature of the intervention being tested.
In summary, the chart provides a nuanced view of LLM performance, moving beyond simple "state-of-the-art" rankings to show how different models react across a diverse set of challenges. The key takeaway is the lack of a universally superior model and the presence of significant task-specific trade-offs, particularly concerning code generation.
DECODING INTELLIGENCE...