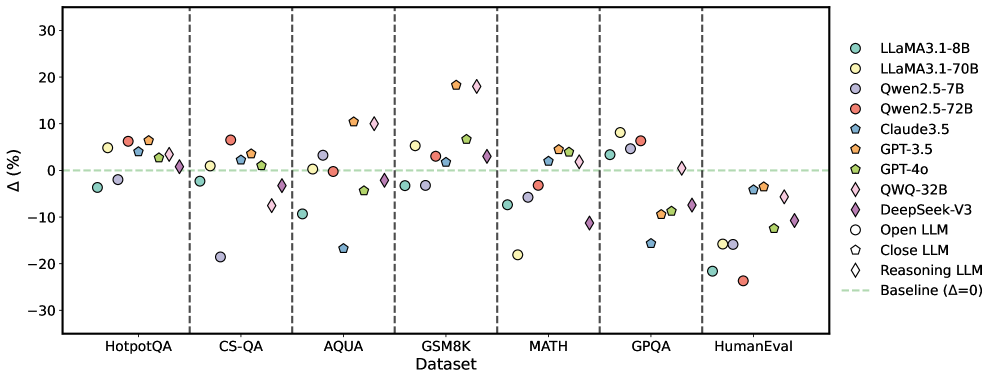
## Scatter Plot: Language Model Performance Comparison Across Datasets
### Overview
The image is a scatter plot comparing the performance of various large language models (LLMs) across multiple question-answering datasets. The y-axis represents percentage change (Δ%) relative to a baseline (Δ=0), while the x-axis lists seven datasets: HotpotQA, CS-QA, AQUA, GSM8K, MATH, GPQA, and HumanEval. Different models are represented by distinct colors and shapes, with a green dashed line indicating the baseline performance.
### Components/Axes
- **X-axis (Dataset)**: Categorical axis with seven question-answering datasets:
- HotpotQA
- CS-QA
- AQUA
- GSM8K
- MATH
- GPQA
- HumanEval
- **Y-axis (Δ%)**: Numerical axis ranging from -30% to +30%, with a green dashed line at 0% (baseline).
- **Legend**: Located on the right, mapping 10 models to colors/shapes:
- LLaMA3.1-8B (teal circles)
- LLaMA3.1-70B (yellow circles)
- Qwen2.5-7B (purple circles)
- Qwen2.5-72B (red circles)
- Claude3.5 (blue pentagons)
- GPT-3.5 (orange pentagons)
- GPT-4o (green hexagons)
- QWQ-32B (pink diamonds)
- DeepSeek-V3 (purple diamonds)
- Open LLM (open circles)
- Close LLM (open pentagons)
- Reasoning LLM (open diamonds)
### Detailed Analysis
- **Dataset Performance**:
- **HotpotQA**: Most models cluster near baseline (0%), with GPT-4o (+5%) and Qwen2.5-72B (+7%) showing moderate gains.
- **CS-QA**: LLaMA3.1-8B (-8%) and Claude3.5 (-15%) underperform, while GPT-4o (+3%) and QWQ-32B (+6%) improve.
- **AQUA**: GPT-4o (+10%) and DeepSeek-V3 (+8%) lead, while LLaMA3.1-70B (-5%) lags.
- **GSM8K**: GPT-4o (+7%) and QWQ-32B (+9%) outperform, with LLaMA3.1-8B (-3%) near baseline.
- **MATH**: GPT-4o (+5%) and DeepSeek-V3 (+6%) lead, while LLaMA3.1-70B (-10%) declines sharply.
- **GPQA**: GPT-4o (+12%) and QWQ-32B (+15%) dominate, with LLaMA3.1-8B (-5%) underperforming.
- **HumanEval**: GPT-4o (+8%) and DeepSeek-V3 (+10%) excel, while LLaMA3.1-70B (-15%) and Qwen2.5-72B (-20%) decline significantly.
- **Model Trends**:
- **GPT-4o** (green hexagons): Consistently above baseline across all datasets, with strongest gains in GPQA (+12%) and HumanEval (+10%).
- **DeepSeek-V3** (purple diamonds): High performance in GPQA (+15%) and HumanEval (+10%), but underperforms in CS-QA (-12%).
- **LLaMA3.1-70B** (yellow circles): Mixed results, with notable declines in MATH (-10%) and HumanEval (-15%).
- **Claude3.5** (blue pentagons): Underperforms in CS-QA (-15%) and GPQA (-10%), but improves in AQUA (+2%).
- **QWQ-32B** (pink diamonds): Strong in GPQA (+15%) and HumanEval (+10%), but declines in CS-QA (-6%).
### Key Observations
1. **GPT-4o and DeepSeek-V3** consistently outperform the baseline across most datasets, with DeepSeek-V3 showing the highest gains in GPQA (+15%).
2. **LLaMA3.1-70B** exhibits significant declines in MATH (-10%) and HumanEval (-15%), suggesting dataset-specific weaknesses.
3. **QWQ-32B** achieves the highest gains in GPQA (+15%) but underperforms in CS-QA (-6%).
4. **Claude3.5** and **LLaMA3.1-8B** show mixed performance, with notable declines in CS-QA and GPQA.
5. **Open LLM** (open circles) and **Close LLM** (open pentagons) are sparsely represented, with most points near or below baseline.
### Interpretation
The plot reveals that **GPT-4o** and **DeepSeek-V3** are the most robust models, excelling in complex reasoning tasks (GPQA, HumanEval). **LLaMA3.1-70B** struggles with mathematical and coding tasks (MATH, HumanEval), while **QWQ-32B** shines in GPQA but falters in CS-QA. The baseline (Δ=0) serves as a critical reference, highlighting models that underperform in specific domains. The variability in performance across datasets underscores the importance of model specialization and dataset alignment. Notably, **reasoning-focused models** (e.g., QWQ-32B, DeepSeek-V3) outperform general-purpose models in structured tasks, suggesting architectural or training advantages for complex problem-solving.