## Chart: Political Persuasion Tweet Win Rates vs Prod GPT-4o
### Overview
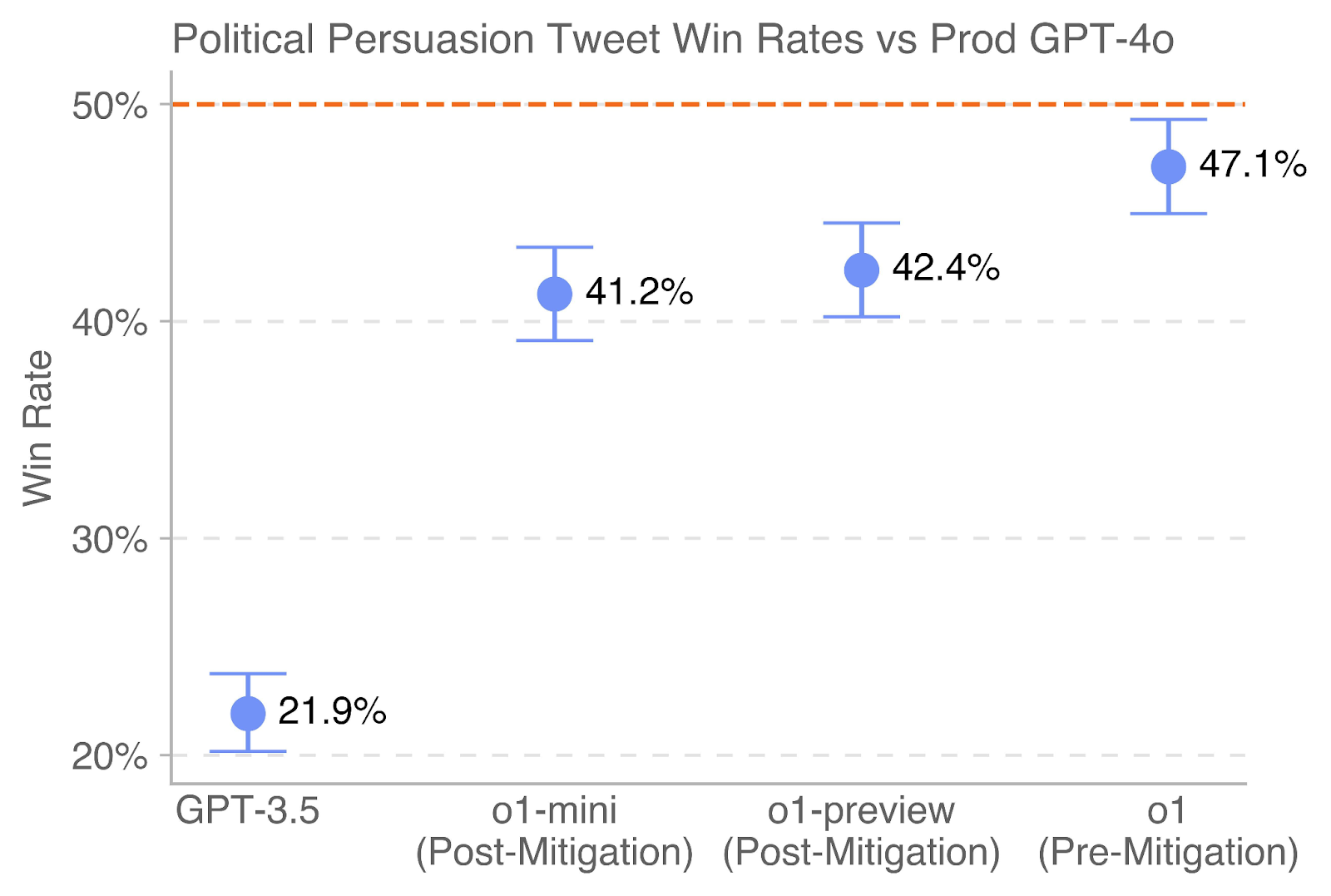
The image is a bar chart comparing the "Win Rate" (presumably success rate) of "Political Persuasion Tweets" generated by different versions of GPT models, including GPT-3.5, o1-mini (Post-Mitigation), o1-preview (Post-Mitigation), and o1 (Pre-Mitigation). The chart also includes a horizontal line at 50%.
### Components/Axes
* **Title:** Political Persuasion Tweet Win Rates vs Prod GPT-4o
* **Y-axis:**
* Label: Win Rate
* Scale: 20% to 50% in 10% increments.
* **X-axis:**
* Categories: GPT-3.5, o1-mini (Post-Mitigation), o1-preview (Post-Mitigation), o1 (Pre-Mitigation)
* **Data Representation:** Each category on the x-axis has a blue data point representing the win rate, with error bars indicating the range of uncertainty.
* **Horizontal Line:** A dashed orange line is present at the 50% win rate mark.
### Detailed Analysis
Here's a breakdown of the win rates for each GPT model, including the approximate range of the error bars:
* **GPT-3.5:**
* Win Rate: 21.9%
* Error Bar Range: Approximately 20% to 24%
* **o1-mini (Post-Mitigation):**
* Win Rate: 41.2%
* Error Bar Range: Approximately 39% to 43%
* **o1-preview (Post-Mitigation):**
* Win Rate: 42.4%
* Error Bar Range: Approximately 40% to 44%
* **o1 (Pre-Mitigation):**
* Win Rate: 47.1%
* Error Bar Range: Approximately 45% to 49%
* **Horizontal Line:**
* Value: 50%
**Trend Verification:** The win rates generally increase from GPT-3.5 to o1 (Pre-Mitigation).
### Key Observations
* GPT-3.5 has a significantly lower win rate compared to the other models.
* The "o1" models (mini, preview, and pre-mitigation) have substantially higher win rates than GPT-3.5.
* The "o1 (Pre-Mitigation)" model has the highest win rate among the models tested.
* All models are below the 50% win rate threshold, indicated by the horizontal line.
### Interpretation
The data suggests that the "o1" models, particularly the "o1 (Pre-Mitigation)" version, are more effective at generating political persuasion tweets compared to GPT-3.5. The "Post-Mitigation" versions of "o1" (mini and preview) show a slight decrease in win rate compared to the "Pre-Mitigation" version, which could indicate the impact of mitigation strategies on the model's persuasive capabilities. The fact that all models are below the 50% threshold suggests that there is still room for improvement in generating highly persuasive political tweets. The error bars indicate the uncertainty in the win rates, but the overall trend remains consistent.