\n
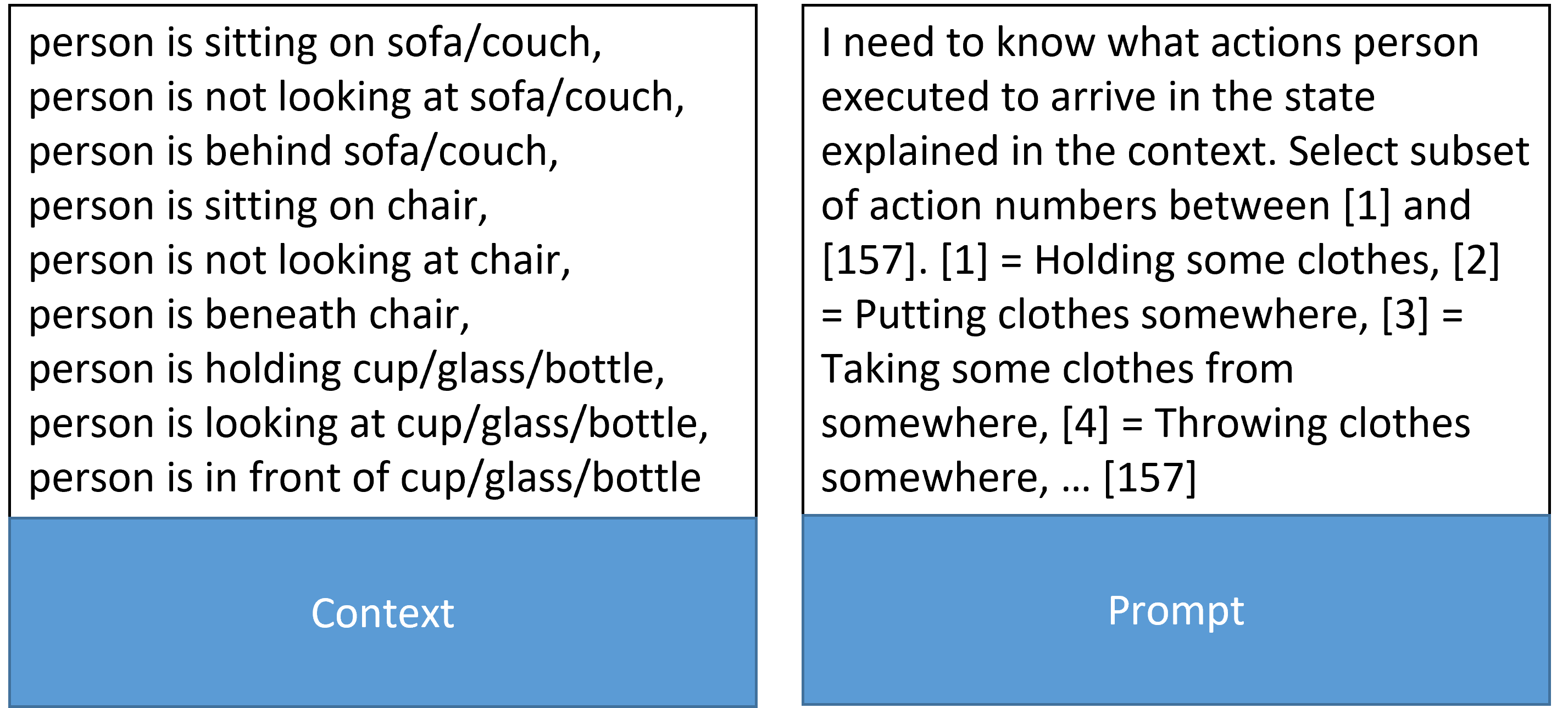
## Screenshot: Context and Prompt
### Overview
The image is a screenshot displaying two rectangular blocks of text, visually separated by color. The left block is labeled "Context" and has a blue background. The right block is labeled "Prompt" and has a light-green background. The screenshot appears to represent an input/output pair for a language model or similar system.
### Components/Axes
The image contains two main components:
* **Context Block:** Labeled "Context" at the bottom-center, with a blue background.
* **Prompt Block:** Labeled "Prompt" at the bottom-center, with a light-green background.
There are no axes or scales present. The content is purely textual.
### Detailed Analysis or Content Details
**Context Block (Blue Background):**
The context block contains the following statements:
1. person is sitting on sofa/couch
2. person is not looking at sofa/couch
3. person is behind sofa/couch
4. person is sitting on chair
5. person is not looking at chair
6. person is beneath chair
7. person is holding cup/glass/bottle
8. person is looking at cup/glass/bottle
9. person is in front of cup/glass/bottle
**Prompt Block (Light-Green Background):**
The prompt block contains the following text:
"I need to know what actions person executed to arrive in the state explained in the context. Select subset of action numbers between [1] and [157]. [1] = Holding some clothes, [2] = Putting clothes somewhere, [3] = Taking some clothes from somewhere, [4] = Throwing clothes somewhere, … [157]"
### Key Observations
The context block describes a scene involving a person and various objects (sofa, chair, cup/glass/bottle). The prompt requests information about actions the person took to reach the described state, referencing a numbered list of actions from 1 to 157, with examples provided for actions 1 through 4. The prompt implies that the context describes a *resulting* state, and the system is asked to infer the actions that *led* to that state. The ellipsis ("… [157]") indicates that the full list of actions is not shown, implying a larger, more complex action space. The use of "person" throughout suggests a focus on agent behavior and state transitions. The prompt is designed to test the ability of a system to understand spatial relationships ("behind", "beneath", "in front of") and infer causal relationships between actions and states.
### Interpretation
This screenshot likely represents a setup for a reasoning task. The "Context" provides observational data, and the "Prompt" poses a question requiring inference about the sequence of events that led to the observed state. The numbered actions suggest a predefined action space, and the task is to select the relevant actions from that space based on the context. The ellipsis ("… [157]") indicates that the full list of actions is not shown, implying a larger, more complex action space. The use of "person" throughout suggests a focus on agent behavior and state transitions. The prompt is designed to test the ability of a system to understand spatial relationships ("behind", "beneath", "in front of") and infer causal relationships between actions and states.