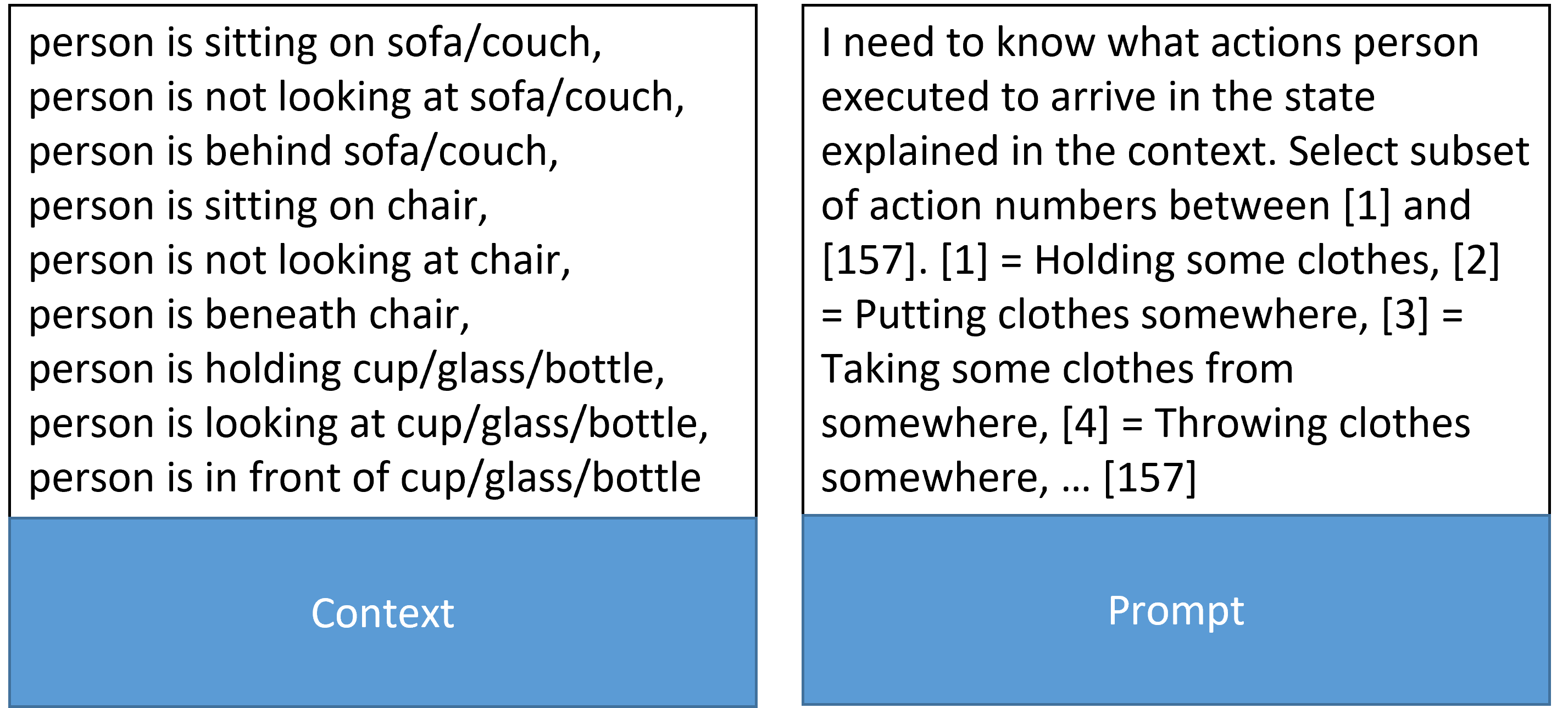
## Screenshot: Context and Prompt for Action Recognition Task
### Overview
The image displays a structured text-based interface divided into two sections: **Context** (left) and **Prompt** (right). The Context outlines positional relationships between a "person" and objects (sofa/couch, chair, cup/glass/bottle), while the Prompt defines a task to map these states to predefined action numbers (1–157). The layout suggests a machine learning or NLP application for action recognition.
---
### Components/Axes
- **Context Section**:
- Describes spatial/temporal states of a person relative to objects:
- Positional states (e.g., "sitting on sofa/couch," "beneath chair").
- Gaze states (e.g., "not looking at sofa/couch").
- Object interactions (e.g., "holding cup/glass/bottle").
- Total of 12 distinct states listed.
- **Prompt Section**:
- Instructions: "Select subset of action numbers between [1] and [157]" to explain the person's state.
- Action-number mappings (examples):
- [1] = Holding some clothes
- [2] = Putting clothes somewhere
- [3] = Taking some clothes from somewhere
- [4] = Throwing clothes somewhere
- [...] (up to [157]).
---
### Detailed Analysis
#### Context Section
1. **Positional States**:
- Sitting on sofa/couch
- Sitting on chair
- Beneath chair
- Behind sofa/couch
- In front of cup/glass/bottle
2. **Gaze States**:
- Not looking at sofa/couch
- Not looking at chair
3. **Object Interactions**:
- Holding cup/glass/bottle
- Looking at cup/glass/bottle
#### Prompt Section
- **Task Objective**: Map Context states to action numbers (1–157).
- **Action Examples**:
- [1] = Holding some clothes
- [2] = Putting clothes somewhere
- [3] = Taking some clothes from somewhere
- [4] = Throwing clothes somewhere
- [...] (157 total actions, with ellipsis indicating continuation).
---
### Key Observations
1. **Context-Prompt Relationship**:
- The Context provides input states, while the Prompt defines output actions. This implies a mapping task (e.g., training a model to associate states with actions).
2. **Ambiguity in Action Numbers**:
- Only 4/157 actions are explicitly defined. The ellipsis suggests the full list is extensive but incomplete in the image.
3. **Object-Specific States**:
- The Context focuses on interactions with furniture (sofa/couch, chair) and containers (cup/glass/bottle), while the Prompt actions center on clothing manipulation. This may indicate a multi-modal task (e.g., combining object interactions with clothing actions).
---
### Interpretation
- **Purpose**: The image likely represents a dataset or task design for action recognition in videos or text descriptions. The Context captures observable states, while the Prompt defines action labels for supervised learning.
- **Design Implications**:
- The lack of explicit mappings between Context states and action numbers suggests the need for additional training data or rules to link them.
- The inclusion of gaze states (e.g., "not looking at...") implies the model must infer actions from both physical interactions and attention.
- **Potential Challenges**:
- Scalability: With 157 actions, the model must handle high-dimensional output spaces.
- Ambiguity: Overlapping states (e.g., "holding cup" vs. "looking at cup") may require context-aware disambiguation.
---
### Conclusion
This interface outlines a framework for action recognition, emphasizing the need to bridge contextual states (e.g., positions, gaze) with discrete actions. Further details (e.g., full action list, training data) would be required to fully operationalize this task.