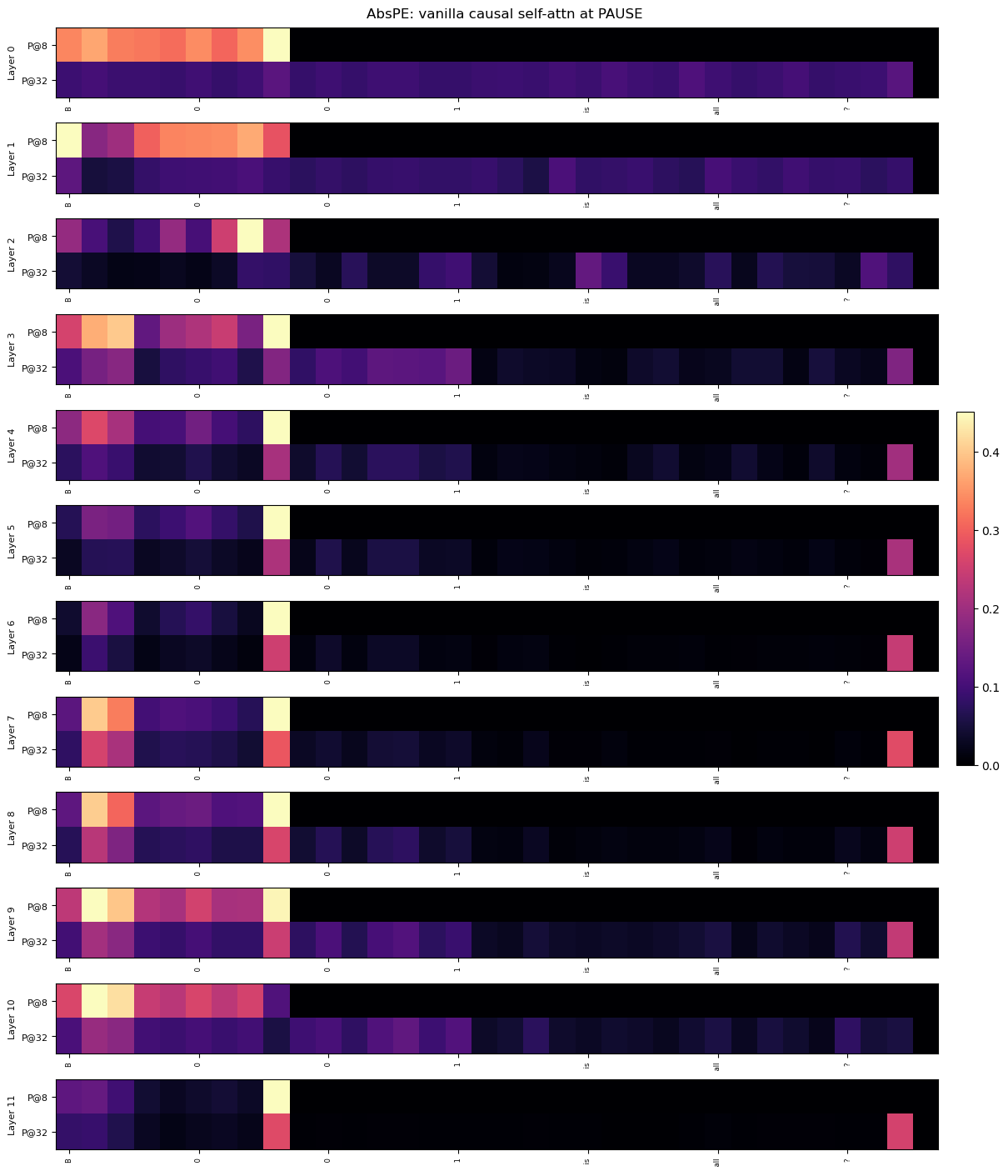
## Heatmap: AbsPE: vanilla causal self-attn at PAUSE
### Overview
The image presents a series of heatmaps, each representing a layer (0 to 11) of a neural network, specifically showing the attention weights of a "vanilla causal self-attention" mechanism at the "PAUSE" token. Each layer has two rows, labeled "P@8" and "P@32", likely representing different configurations or parameter settings. The columns represent different tokens in the input sequence. The color intensity indicates the attention weight, ranging from dark purple (low attention) to bright yellow (high attention), as indicated by the colorbar on the right.
### Components/Axes
* **Title:** AbsPE: vanilla causal self-attn at PAUSE
* **Y-axis:** "Layer" (0 to 11), with each layer having two sub-rows labeled "P@8" and "P@32".
* **X-axis:** Tokens in the input sequence, labeled "8", "0", "1", "is", "all", "?".
* **Colorbar:** Ranges from 0.0 (dark purple) to 0.4 (bright yellow), with intermediate values of 0.1, 0.2, and 0.3. The colorbar is located on the right side of the image.
### Detailed Analysis
Each row in the heatmap represents the attention weights for a specific layer and configuration (P@8 or P@32). The intensity of each cell indicates the strength of attention between the token represented by the column and the token being attended to in that layer.
**Layer 0:**
* P@8: High attention (yellow/orange) to tokens "8" and "0", moderate attention (red) to "1", "is", and "all", and low attention (purple) to "?".
* P@32: Moderate attention (red) to tokens "8" and "0", low attention (purple) to "1", "is", "all", and "?".
**Layer 1:**
* P@8: High attention (yellow/orange) to tokens "8" and "0", moderate attention (red) to "1", "is", and "all", and low attention (purple) to "?".
* P@32: Low attention (purple) to all tokens.
**Layer 2:**
* P@8: Low attention (purple) to "8", moderate attention (red) to "0", low attention (purple) to "1", "is", and "all", and moderate attention (red) to "?".
* P@32: Low attention (purple) to all tokens.
**Layer 3:**
* P@8: High attention (yellow/orange) to tokens "8" and "0", moderate attention (red) to "1", "is", and "all", and low attention (purple) to "?".
* P@32: Low attention (purple) to all tokens.
**Layer 4:**
* P@8: Moderate attention (red) to tokens "8" and "0", low attention (purple) to "1", "is", and "all", and moderate attention (red) to "?".
* P@32: Low attention (purple) to all tokens.
**Layer 5:**
* P@8: Low attention (purple) to all tokens except for a moderate attention (red) to "?".
* P@32: Low attention (purple) to all tokens.
**Layer 6:**
* P@8: Low attention (purple) to all tokens except for a moderate attention (red) to "?".
* P@32: Low attention (purple) to all tokens.
**Layer 7:**
* P@8: High attention (yellow/orange) to tokens "8" and "0", moderate attention (red) to "1", "is", and "all", and low attention (purple) to "?".
* P@32: Low attention (purple) to all tokens except for a moderate attention (red) to "?".
**Layer 8:**
* P@8: High attention (yellow/orange) to tokens "8" and "0", moderate attention (red) to "1", "is", and "all", and low attention (purple) to "?".
* P@32: Low attention (purple) to all tokens except for a moderate attention (red) to "?".
**Layer 9:**
* P@8: High attention (yellow/orange) to tokens "8" and "0", moderate attention (red) to "1", "is", and "all", and low attention (purple) to "?".
* P@32: Low attention (purple) to all tokens except for a moderate attention (red) to "?".
**Layer 10:**
* P@8: High attention (yellow/orange) to tokens "8" and "0", moderate attention (red) to "1", "is", and "all", and low attention (purple) to "?".
* P@32: Low attention (purple) to all tokens except for a moderate attention (red) to "?".
**Layer 11:**
* P@8: Low attention (purple) to all tokens except for a moderate attention (red) to "?".
* P@32: Low attention (purple) to all tokens except for a moderate attention (red) to "?".
### Key Observations
* The "P@8" configuration generally shows higher attention weights compared to "P@32".
* Layers 0, 1, 3, 7, 8, 9, and 10 show high attention to the initial tokens "8" and "0" in the "P@8" configuration.
* Layers 2, 4, 5, 6, and 11 show moderate attention to the "?" token in the "P@8" configuration.
* The "P@32" configuration generally shows low attention weights across all tokens, except for the "?" token in some layers.
### Interpretation
The heatmaps visualize the attention mechanism of a neural network at different layers. The higher attention weights to the initial tokens ("8" and "0") in the lower layers (0, 1, 3, 7, 8, 9, and 10) suggest that these layers are focusing on the beginning of the input sequence. The increased attention to the "?" token in the higher layers (2, 4, 5, 6, and 11) might indicate that these layers are focusing on the end of the sequence or are involved in question answering. The difference in attention patterns between "P@8" and "P@32" suggests that these configurations have different learning dynamics or are sensitive to different aspects of the input. The "P@32" configuration seems to have a more focused attention on the "?" token in the later layers, while "P@8" has a broader attention span in the earlier layers.