## Heatmap: AbsPE - Vanilla Causal Self-Attention at PAUSE
### Overview
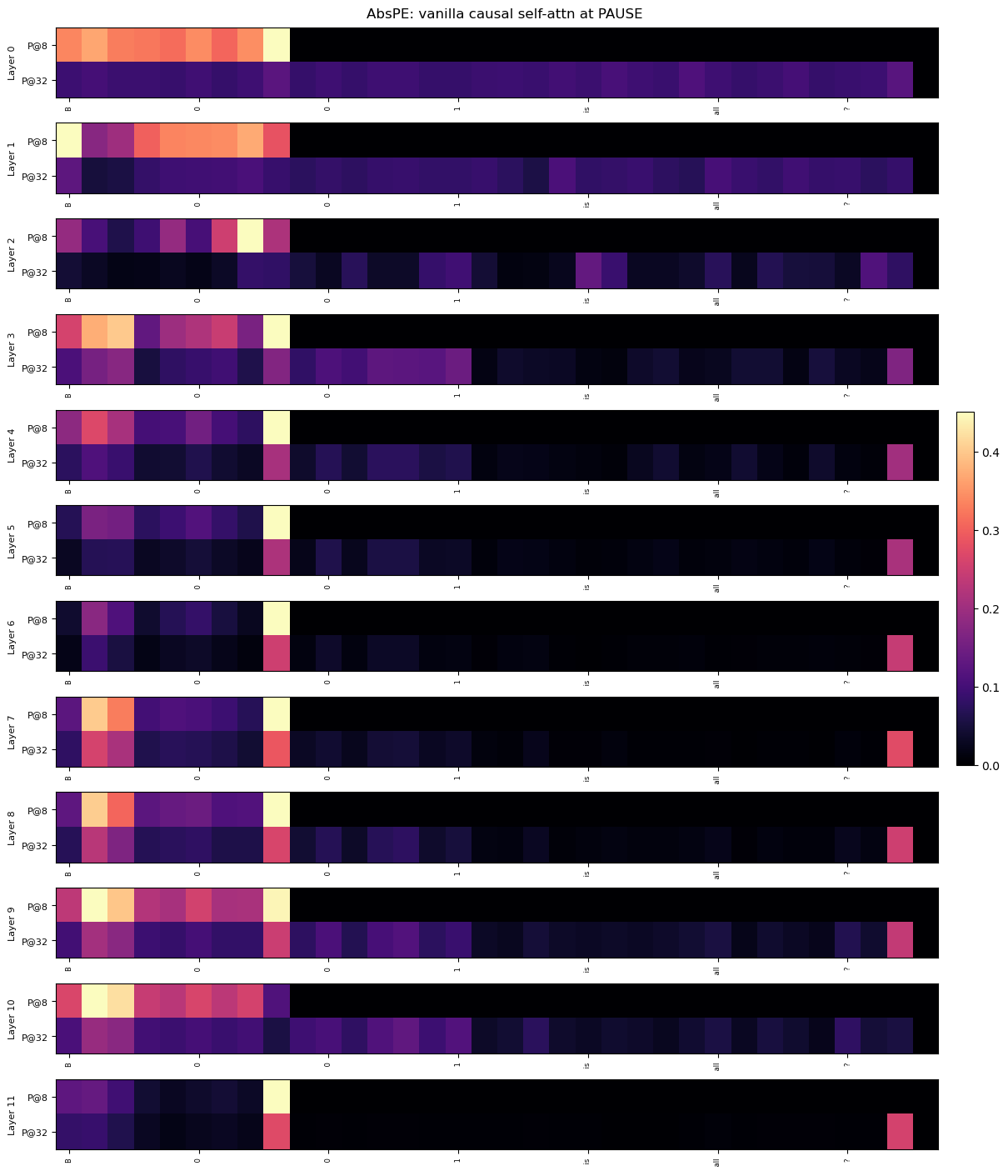
The image presents a series of heatmaps, stacked vertically, representing the attention weights within a neural network model (AbsPE) at a specific point ("PAUSE"). Each heatmap corresponds to a different layer of the model, ranging from Layer 0 to Layer 11. The heatmaps visualize the attention distribution between different positions (Pg8 and Pg32) within each layer. The color intensity indicates the strength of the attention weight, with a scale ranging from 0.0 to 0.4.
### Components/Axes
* **Title:** AbsPE: vanilla causal self-attn at PAUSE (top-center)
* **Y-axis:** Represents the layer number, labeled "Layer 0" to "Layer 11" (left side).
* **X-axis:** Represents positions, labeled "Pg8" and "Pg32" (bottom). There are also intermediate tick marks labeled "0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "10", "11", "12", "13", "14", "15", "16", "17", "18", "19", "20", "21", "22", "23", "24", "25", "26", "27", "28", "29", "30", "31"
* **Colorbar:** Located on the right side, indicating the attention weight scale from 0.0 (dark purple) to 0.4 (yellow).
### Detailed Analysis
Each heatmap is a 2x32 grid, representing the attention weights between Pg8 and Pg32 across 32 positions. The color intensity within each cell corresponds to the attention weight.
Here's a layer-by-layer breakdown of the observed attention patterns (approximate values based on color mapping):
* **Layer 0:** High attention weights (around 0.3-0.4) are concentrated in the first few positions for Pg8, decreasing towards zero for Pg32.
* **Layer 1:** Similar to Layer 0, high attention weights (around 0.3-0.4) are concentrated in the first few positions for Pg8, decreasing towards zero for Pg32.
* **Layer 2:** High attention weights (around 0.3-0.4) are concentrated in the first few positions for Pg8, decreasing towards zero for Pg32.
* **Layer 3:** High attention weights (around 0.3-0.4) are concentrated in the first few positions for Pg8, decreasing towards zero for Pg32.
* **Layer 4:** High attention weights (around 0.3-0.4) are concentrated in the first few positions for Pg8, decreasing towards zero for Pg32.
* **Layer 5:** High attention weights (around 0.3-0.4) are concentrated in the first few positions for Pg8, decreasing towards zero for Pg32.
* **Layer 6:** High attention weights (around 0.3-0.4) are concentrated in the first few positions for Pg8, decreasing towards zero for Pg32.
* **Layer 7:** High attention weights (around 0.3-0.4) are concentrated in the first few positions for Pg8, decreasing towards zero for Pg32.
* **Layer 8:** High attention weights (around 0.3-0.4) are concentrated in the first few positions for Pg8, decreasing towards zero for Pg32.
* **Layer 9:** A significant shift in attention pattern. High attention weights (around 0.3-0.4) are observed in the later positions for Pg8, and a broader distribution of moderate attention weights (around 0.1-0.2) for Pg32.
* **Layer 10:** Similar to Layer 9, high attention weights (around 0.3-0.4) are observed in the later positions for Pg8, and a broader distribution of moderate attention weights (around 0.1-0.2) for Pg32.
* **Layer 11:** Similar to Layers 9 and 10, high attention weights (around 0.3-0.4) are observed in the later positions for Pg8, and a broader distribution of moderate attention weights (around 0.1-0.2) for Pg32.
### Key Observations
* The attention patterns in Layers 0-8 are consistent, with strong attention focused on the initial positions for Pg8 and minimal attention for Pg32.
* A clear shift in attention occurs starting from Layer 9, where attention becomes more distributed and focused on later positions for both Pg8 and Pg32.
* The attention weights for Pg32 remain generally lower than those for Pg8, except in Layers 9-11 where they become more significant.
* The colorbar indicates that the maximum attention weight observed is approximately 0.4.
### Interpretation
The heatmaps demonstrate how the model's attention mechanism evolves across different layers. The initial layers (0-8) appear to focus on processing information from the beginning of the sequence (Pg8), while later layers (9-11) exhibit a broader attention distribution, suggesting that the model is learning to consider information from later positions (Pg32) as well. This shift in attention could indicate that the model is capturing long-range dependencies or integrating information from different parts of the input sequence. The consistent low attention weights for Pg32 in the early layers might suggest that this position is initially less relevant to the model's processing, but its importance increases as the information propagates through the network. The "PAUSE" point likely represents a state where the model has processed a significant portion of the input and is beginning to integrate information across the entire sequence. The observed patterns suggest that the model is transitioning from a local to a more global understanding of the input data.