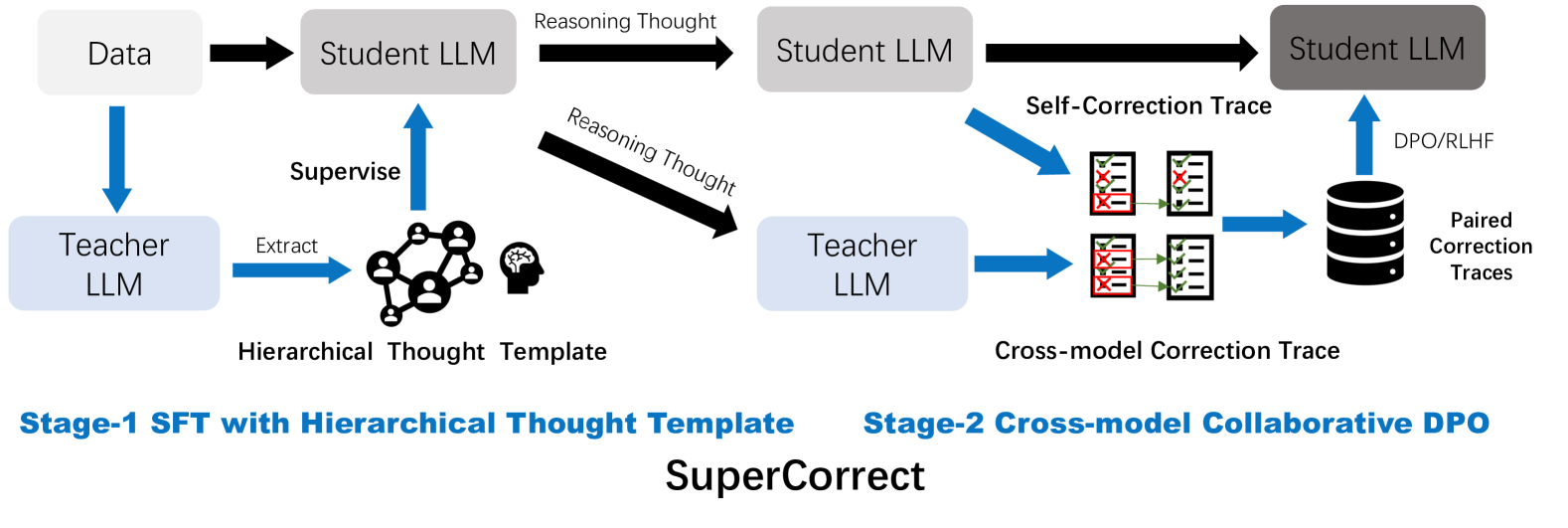
## Diagram: SuperCorrect
### Overview
The image is a diagram illustrating the "SuperCorrect" process, which involves two stages: Stage-1 SFT (Supervised Fine-Tuning) with Hierarchical Thought Template and Stage-2 Cross-model Collaborative DPO (Direct Preference Optimization). The diagram shows the flow of data and reasoning between Student LLMs (Large Language Models) and Teacher LLMs, incorporating self-correction and cross-model correction traces.
### Components/Axes
* **Data:** Input data for the process.
* **Student LLM:** Large Language Model being trained. Represented by a gray rounded rectangle.
* **Teacher LLM:** Large Language Model used for supervision and correction. Represented by a light blue rounded rectangle.
* **Reasoning Thought:** Represents the reasoning process of the LLMs.
* **Hierarchical Thought Template:** A structured representation of knowledge used for supervision.
* **Self-Correction Trace:** Correction traces generated by the Student LLM.
* **Cross-model Correction Trace:** Correction traces generated by the Teacher LLM.
* **Paired Correction Traces:** A database of correction traces used for DPO/RLHF.
* **DPO/RLHF:** Direct Preference Optimization/Reinforcement Learning from Human Feedback.
* **Arrows:** Indicate the flow of data, reasoning, and supervision.
### Detailed Analysis
**Stage-1: SFT with Hierarchical Thought Template**
1. **Data** flows into a **Student LLM** (black arrow).
2. The **Student LLM** generates **Reasoning Thought** (black arrow) which flows into another **Student LLM**.
3. A **Teacher LLM** is supervised by the **Hierarchical Thought Template** (blue arrow).
4. The **Hierarchical Thought Template** extracts information from a network diagram and a head icon (blue arrow).
5. The **Teacher LLM** extracts information from the **Hierarchical Thought Template** (blue arrow).
6. The **Reasoning Thought** also flows diagonally into the **Teacher LLM** (black arrow).
**Stage-2: Cross-model Collaborative DPO**
1. The **Student LLM** generates **Reasoning Thought** (black arrow) which flows into another **Student LLM**.
2. The **Student LLM** generates **Self-Correction Traces** (blue arrow). These traces are represented by two documents, each with checkmarks and red 'X' marks, indicating corrections.
3. The **Teacher LLM** generates **Cross-model Correction Traces** (blue arrow). These traces are represented by two documents, each with checkmarks and red 'X' marks, indicating corrections.
4. Both **Self-Correction Traces** and **Cross-model Correction Traces** are stored as **Paired Correction Traces** (blue arrows) in a database.
5. The **Paired Correction Traces** are used for **DPO/RLHF** (blue arrow) to improve the **Student LLM**.
### Key Observations
* The diagram illustrates a two-stage process for improving LLMs.
* Stage 1 focuses on supervised fine-tuning using a hierarchical thought template.
* Stage 2 focuses on collaborative correction using both self-correction and cross-model correction traces.
* The use of DPO/RLHF in Stage 2 suggests a reinforcement learning approach to further refine the LLM.
### Interpretation
The "SuperCorrect" process aims to enhance LLMs by combining supervised fine-tuning with collaborative correction and reinforcement learning. The hierarchical thought template provides structured knowledge for supervision, while the self-correction and cross-model correction traces enable the LLM to learn from its own mistakes and the corrections provided by a teacher model. The use of DPO/RLHF allows for further refinement of the LLM based on preference data. This approach leverages the strengths of both supervised and reinforcement learning to create more accurate and reliable LLMs.