\n
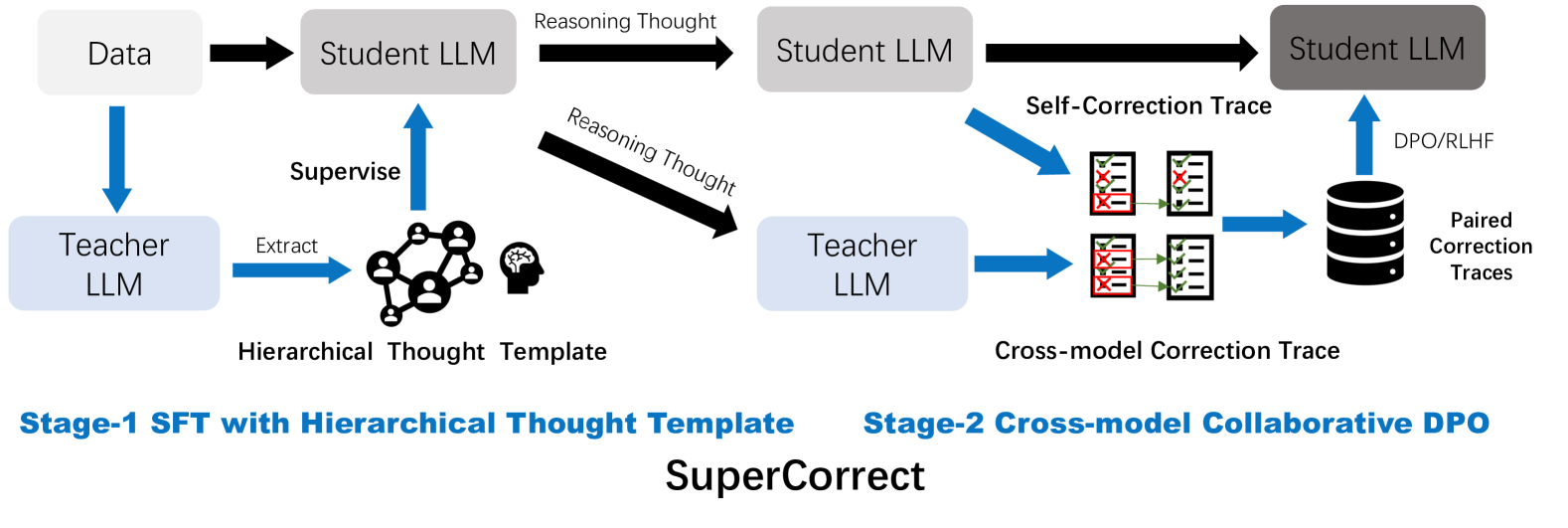
## Diagram: SuperCorrect - A Two-Stage LLM Training Pipeline
### Overview
This diagram illustrates a two-stage training pipeline called "SuperCorrect" for Large Language Models (LLMs). The pipeline consists of Stage-1, Supervised Fine-Tuning (SFT) with a Hierarchical Thought Template, and Stage-2, Cross-model Collaborative Direct Preference Optimization (DPO). The diagram depicts the flow of data and reasoning between a "Teacher LLM" and a "Student LLM" across these two stages.
### Components/Axes
The diagram is divided into two main stages, labeled "Stage-1 SFT with Hierarchical Thought Template" and "Stage-2 Cross-model Collaborative DPO". Key components include:
* **Data:** The initial input to the system.
* **Teacher LLM:** A model used to supervise and extract information.
* **Student LLM:** The model being trained.
* **Hierarchical Thought Template:** A representation of structured reasoning, depicted as a network of interconnected nodes.
* **Self-Correction Trace:** Data generated during the student LLM's self-correction process.
* **Cross-model Correction Trace:** Data generated during the teacher LLM's correction of the student LLM.
* **DPO/RLHF:** Direct Preference Optimization and Reinforcement Learning from Human Feedback, used in Stage-2.
* **Paired Correction Traces:** The output of the correction process, stored in a database.
* **Arrows:** Indicate the flow of data and reasoning.
### Detailed Analysis or Content Details
**Stage-1: SFT with Hierarchical Thought Template**
1. **Data Input:** Data flows from the left into the "Student LLM".
2. **Reasoning Thought:** The "Student LLM" generates "Reasoning Thought" which is represented by a horizontal arrow.
3. **Teacher Supervision:** The "Teacher LLM" receives data directly and also supervises the "Student LLM" via an arrow labeled "Supervise".
4. **Thought Extraction:** The "Teacher LLM" extracts information to create a "Hierarchical Thought Template", visually represented as a complex network of nodes and connections. The text "Hierarchical Thought Template" is directly below this network.
**Stage-2: Cross-model Collaborative DPO**
1. **Student LLM Reasoning:** The "Student LLM" generates "Reasoning Thought" again, similar to Stage-1.
2. **Self-Correction:** The "Student LLM" generates a "Self-Correction Trace". This is visually represented by two stacks of red and white boxes.
3. **Cross-model Correction:** The "Teacher LLM" generates a "Cross-model Correction Trace", also represented by two stacks of red and white boxes.
4. **Data Storage:** Both "Self-Correction Trace" and "Cross-model Correction Trace" are fed into a database cylinder labeled "Paired Correction Traces".
5. **DPO/RLHF Application:** The database output is used for "DPO/RLHF" (Direct Preference Optimization/Reinforcement Learning from Human Feedback).
### Key Observations
* The diagram emphasizes a collaborative approach between a "Teacher" and "Student" LLM.
* The "Hierarchical Thought Template" appears to be a key component in structuring the reasoning process.
* The second stage focuses on iterative correction and refinement of the "Student LLM" using traces from both self-correction and teacher feedback.
* The use of DPO/RLHF suggests a preference-based learning approach in the final stage.
* The visual representation of traces as stacks of boxes suggests a structured data format.
### Interpretation
The "SuperCorrect" pipeline aims to improve LLM performance through a two-stage process. Stage-1 focuses on learning a structured reasoning process using a "Hierarchical Thought Template" guided by a "Teacher LLM". Stage-2 leverages the insights from both self-correction and teacher feedback to refine the "Student LLM" using DPO/RLHF. The diagram suggests a focus on not just generating outputs, but also on understanding and correcting the reasoning process behind those outputs. The use of paired correction traces indicates a comparative learning approach, where the system learns from its own mistakes and the corrections provided by the teacher. The overall architecture suggests a sophisticated training methodology designed to enhance the reliability and accuracy of LLMs.