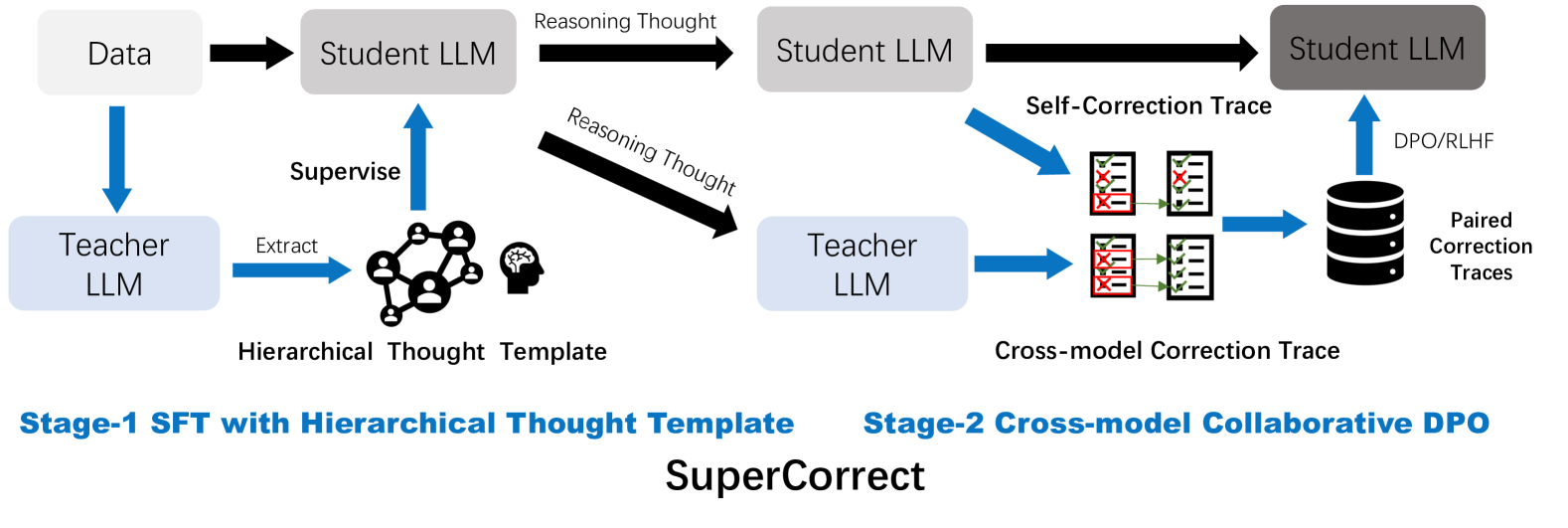
\n
## Diagram: SuperCorrect System Architecture
### Overview
The image is a technical process diagram illustrating a two-stage framework named "SuperCorrect." It depicts a machine learning training pipeline involving "Teacher LLM" and "Student LLM" models, focusing on generating and utilizing reasoning and correction traces to improve model performance. The diagram is divided into two distinct stages, labeled at the bottom.
### Components/Axes
The diagram is organized horizontally into two main sections, with a central title.
**Title (Bottom Center):** `SuperCorrect`
**Stage Labels (Bottom):**
* **Left Side:** `Stage-1 SFT with Hierarchical Thought Template`
* **Right Side:** `Stage-2 Cross-model Collaborative DPO`
**Primary Components (Boxes & Icons):**
1. **Data** (Light gray box, top-left)
2. **Student LLM** (Three instances: light gray box top-left, medium gray box top-center, dark gray box top-right)
3. **Teacher LLM** (Two instances: light blue box mid-left, light blue box mid-center)
4. **Hierarchical Thought Template** (Icon: network of people connected to a brain silhouette, center-left)
5. **Paired Correction Traces** (Database icon, right side)
6. **Correction Trace Icons** (Two sets of document icons with red 'X's and green checkmarks, center-right)
**Flow & Process Labels (Text on Arrows and Connectors):**
* `Extract` (Blue arrow from left Teacher LLM to Hierarchical Thought Template)
* `Supervise` (Blue arrow from Hierarchical Thought Template to first Student LLM)
* `Reasoning Thought` (Two black arrows: one from first to second Student LLM, one from first Student LLM to right Teacher LLM)
* `Self-Correction Trace` (Blue arrow from second Student LLM to upper set of correction trace icons)
* `Cross-model Correction Trace` (Blue arrow from right Teacher LLM to lower set of correction trace icons)
* `DPO/RLHF` (Blue arrow from Paired Correction Traces database to final Student LLM)
### Detailed Analysis
The diagram outlines a sequential, two-stage process:
**Stage-1: SFT with Hierarchical Thought Template**
1. **Input:** `Data` is fed into both a `Student LLM` and a `Teacher LLM`.
2. **Template Creation:** The `Teacher LLM` performs an `Extract` operation to generate a `Hierarchical Thought Template`.
3. **Supervision:** This template is used to `Supervise` the first `Student LLM`.
4. **Output:** The supervised Student LLM produces `Reasoning Thought`, which is passed forward to the next stage (to another Student LLM and a second Teacher LLM).
**Stage-2: Cross-model Collaborative DPO**
1. **Input:** The `Reasoning Thought` from Stage-1 is received by a second `Student LLM` and a second `Teacher LLM`.
2. **Trace Generation:**
* The Student LLM generates a `Self-Correction Trace`.
* The Teacher LLM generates a `Cross-model Correction Trace`.
3. **Trace Aggregation:** Both correction traces (visually represented as documents with errors marked by red 'X's and corrections by green checkmarks) are collected into a database of `Paired Correction Traces`.
4. **Model Update:** The paired traces are used via `DPO/RLHF` (Direct Preference Optimization / Reinforcement Learning from Human Feedback) to update the final `Student LLM`.
### Key Observations
* **Progressive Model Darkening:** The three `Student LLM` boxes progress from light gray to dark gray, visually suggesting iterative improvement or increasing model capability through the stages.
* **Dual Trace Generation:** Stage-2 explicitly involves two models (Student and Teacher) generating correction traces collaboratively, which are then paired.
* **Closed Feedback Loop:** The final output of the process (Paired Correction Traces) is used to update the model itself (DPO/RLHF arrow), creating a feedback loop for continuous improvement.
* **Asymmetric Flow:** The flow is not linear. Data enters at the top-left, but the core process involves a loop where reasoning thoughts are generated, used to create correction traces, and then fed back to refine the model.
### Interpretation
The "SuperCorrect" diagram illustrates a sophisticated method for improving Large Language Models (LLMs) through a two-phase approach that emphasizes structured reasoning and error correction.
* **What it demonstrates:** The framework aims to move beyond simple supervised fine-tuning (SFT). Stage-1 instills a structured, hierarchical reasoning capability. Stage-2 then leverages this capability in a collaborative setting where a student model and a teacher model critique each other's outputs, generating a dataset of error-correction pairs. This dataset is then used with advanced alignment techniques (DPO/RLHF) to directly optimize the student model's behavior.
* **Relationship between elements:** The Teacher LLM acts as a guide and critic, first by providing a thought template and later by generating cross-model corrections. The Student LLM is the primary learner, first being supervised and then engaging in self-correction and learning from paired traces. The "Hierarchical Thought Template" is the key artifact of Stage-1, enabling more complex reasoning in Stage-2.
* **Notable implications:** This process suggests a focus on **model self-awareness and error correction** as a path to improved performance. By generating and learning from its own (and a teacher's) correction traces, the model may become more robust and reliable. The use of "collaborative" DPO implies that the preference data for alignment is derived from the dynamic interaction between two models, rather than solely from static human annotations.