# Technical Document Extraction: SuperCorrect Framework
## Diagram Overview
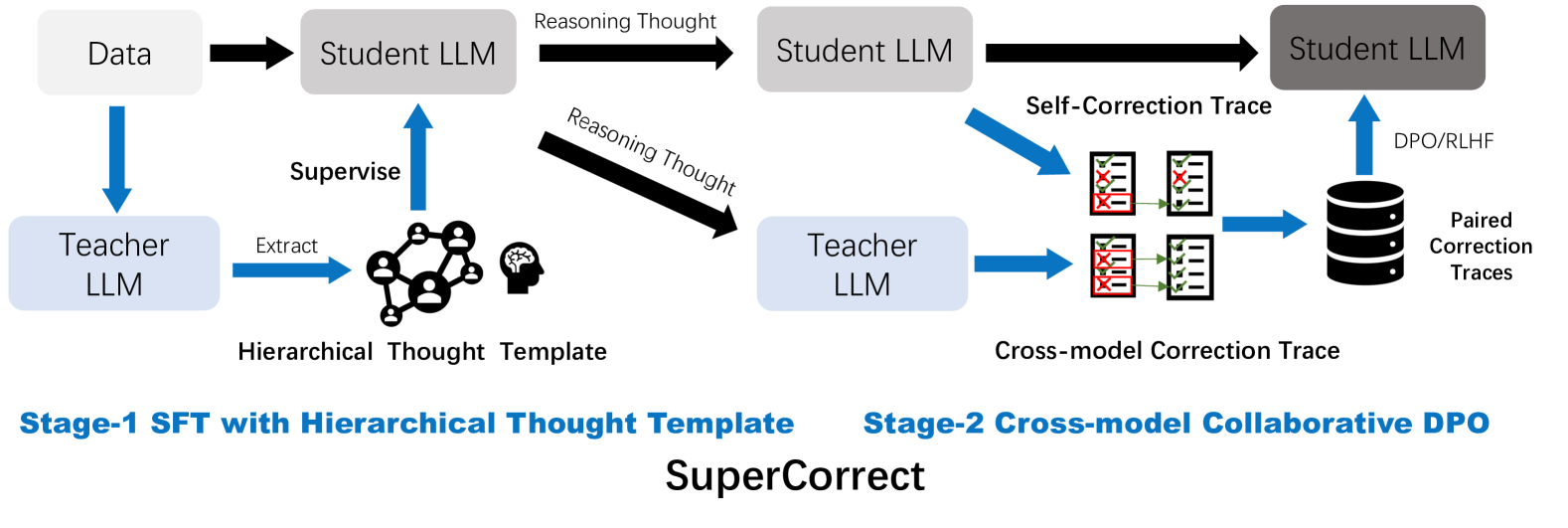
The image depicts a two-stage framework for Large Language Model (LLM) training and correction, labeled **"SuperCorrect"**. It combines **Stage-1 SFT with Hierarchical Thought Template** and **Stage-2 Cross-model Collaborative DPO**. The diagram uses arrows, labeled components, and hierarchical structures to represent data flow and model interactions.
---
## Key Components and Flow
### Stage-1: SFT with Hierarchical Thought Template
1. **Data Input**
- **Source**: Labeled as "Data" (top-left).
- **Flow**: Direct arrow to **Student LLM** (gray box).
2. **Supervision Process**
- **Teacher LLM** (blue box) supervises the Student LLM.
- **Action**: "Supervise" arrow from Teacher LLM to Student LLM.
- **Output**: "Hierarchical Thought Template" (icon: interconnected human figures + brain).
3. **Reasoning Thought Generation**
- **Student LLM** generates "Reasoning Thought" (black arrow).
- **Flow**: Student LLM → Teacher LLM.
4. **Teacher LLM Output**
- **Output**: "Cross-model Correction Trace" (icon: red/green checkmarks).
---
### Stage-2: Cross-model Collaborative DPO
1. **Self-Correction Trace**
- **Source**: Student LLM (gray box).
- **Flow**: Black arrow labeled "Self-Correction Trace" to itself.
2. **Cross-model Correction Trace**
- **Source**: Teacher LLM (blue box).
- **Flow**: Blue arrow labeled "Cross-model Correction Trace" to Student LLM.
3. **DPO/RLHF Integration**
- **Process**: Student LLM receives "DPO/RLHF" (black arrow).
- **Output**: "Paired Correction Traces" (icon: stacked disks).
---
## Textual Labels and Annotations
- **Stage-1 SFT with Hierarchical Thought Template** (bottom-left, blue text).
- **Stage-2 Cross-model Collaborative DPO** (bottom-right, blue text).
- **SuperCorrect** (center-bottom, bold black text).
---
## Spatial Grounding and Component Isolation
- **Header**: Diagram title "SuperCorrect" (center-bottom).
- **Main Chart**:
- **Stage-1** (left): Data → Student LLM → Teacher LLM → Hierarchical Thought Template.
- **Stage-2** (right): Self-Correction Trace ↔ Cross-model Correction Trace → Paired Correction Traces.
- **Footer**: Stage labels (blue text).
---
## Notes on Diagram Structure
- **Arrows**:
- Black arrows represent reasoning/correction traces.
- Blue arrows denote supervision/collaboration.
- **Icons**:
- Human figures + brain: Hierarchical Thought Template.
- Red/green checkmarks: Cross-model Correction Trace.
- Stacked disks: Paired Correction Traces.
---
## Absent Elements
- No numerical data, charts, or tables present.
- No non-English text detected.
---
## Summary
The diagram illustrates a two-phase LLM training pipeline:
1. **Stage-1** focuses on supervised fine-tuning (SFT) using hierarchical thought templates.
2. **Stage-2** employs cross-model collaborative DPO (Direct Preference Optimization) with self-correction and paired traces.
The framework emphasizes iterative refinement through teacher-student interactions and cross-model validation.