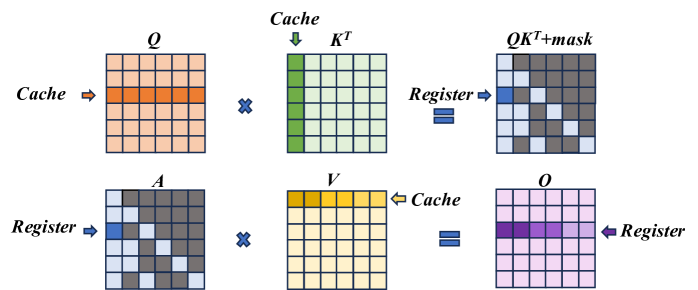
\n
## Diagram: Attention Mechanism Data Flow
### Overview
The image depicts a diagram illustrating the data flow within an attention mechanism, likely within a neural network architecture. It shows a series of matrix operations and data transfers between "Cache" and "Register" memory locations. The diagram is arranged in two rows, each representing a stage of the attention calculation.
### Components/Axes
The diagram consists of six labeled matrices:
* **Q**: Located in the top-left, labeled "Cache".
* **K<sup>T</sup>**: Located in the top-center, labeled "Cache".
* **QKT+mask**: Located in the top-right, labeled "Register".
* **A**: Located in the bottom-left, labeled "Register".
* **V**: Located in the bottom-center, labeled "Cache".
* **O**: Located in the bottom-right, labeled "Register".
Arrows indicate the direction of data flow. Multiplication symbols (x) denote matrix multiplication operations. The equals sign (=) indicates assignment or data transfer.
### Detailed Analysis or Content Details
The diagram shows the following sequence of operations:
1. **Q and K<sup>T</sup> Multiplication:** The matrix **Q** (orange and red squares) from "Cache" is multiplied by the transpose of matrix **K<sup>T</sup>** (mostly white squares with some blue) from "Cache". The result is **QKT+mask** (grey squares with some white and black) and is stored in "Register".
2. **A and V Multiplication:** The matrix **A** (dark grey squares with some light grey) from "Register" is multiplied by the matrix **V** (yellow and orange squares) from "Cache". The result is **O** (purple and pink squares with some white) and is stored in "Register".
The matrices are represented as grids of squares, with different colors indicating different values or data elements. The size of the matrices appears to be approximately 8x8, but the exact dimensions are not explicitly stated. The "mask" component in **QKT+mask** suggests an attention masking operation is being performed.
### Key Observations
The diagram highlights the core steps of an attention mechanism: calculating attention weights (through Q and K) and applying those weights to values (V) to produce an output (O). The use of "Cache" and "Register" suggests these matrices are stored in different memory locations, potentially for efficiency or parallel processing. The masking operation is a key component of attention, allowing the model to focus on relevant parts of the input.
### Interpretation
This diagram illustrates a simplified view of the attention mechanism, a crucial component in modern neural network architectures like Transformers. The attention mechanism allows the model to weigh the importance of different parts of the input sequence when making predictions. The "Q", "K", and "V" matrices represent queries, keys, and values, respectively. The multiplication of Q and K<sup>T</sup> calculates attention weights, which are then used to weight the values (V) to produce the output (O). The mask is used to prevent the model from attending to certain parts of the input, such as padding tokens or future tokens in a sequence. The diagram suggests a computational process where intermediate results are stored in registers for efficient access. The use of Cache implies that these matrices are reused or updated over time, potentially for processing long sequences. The diagram does not provide specific numerical values or dimensions, but it effectively conveys the logical flow of data within the attention mechanism.