\n
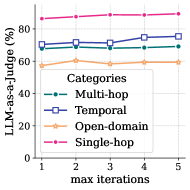
## Line Chart: LLM-as-a-Judge Performance vs. Iterations
### Overview
This image presents a line chart illustrating the performance of a Large Language Model (LLM) as a judge, measured as a percentage, across four different categories of tasks (Multi-hop, Temporal, Open-domain, and Single-hop) as the maximum number of iterations increases from 1 to 5.
### Components/Axes
* **X-axis:** "max iterations" - ranging from 1 to 5.
* **Y-axis:** "LLM-as-a-judge (%)" - ranging from 0 to 80, with markings at 20, 40, 60, and 80.
* **Legend:** Located in the center-right of the chart, listing the four categories:
* Multi-hop (dashed blue line)
* Temporal (blue square line)
* Open-domain (orange line with circle markers)
* Single-hop (pink dashed line)
### Detailed Analysis
Let's analyze each data series:
* **Multi-hop (dashed blue line):** The line starts at approximately 72% at iteration 1, increases slightly to around 74% at iteration 2, remains relatively stable around 73-74% for iterations 3 and 4, and then increases to approximately 75% at iteration 5.
* **Temporal (blue square line):** The line begins at approximately 73% at iteration 1, increases to around 75% at iteration 2, decreases slightly to 74% at iteration 3, increases to approximately 76% at iteration 4, and then decreases to around 75% at iteration 5.
* **Open-domain (orange line with circle markers):** The line starts at approximately 58% at iteration 1, increases gradually to around 60% at iteration 2, remains relatively stable around 60-61% for iterations 3 and 4, and then increases to approximately 62% at iteration 5.
* **Single-hop (pink dashed line):** The line is consistently high, starting at approximately 85% at iteration 1 and remaining nearly constant at around 85-86% for all iterations up to 5.
### Key Observations
* The "Single-hop" category consistently exhibits the highest performance, remaining above 85% across all iterations.
* The "Open-domain" category consistently exhibits the lowest performance, remaining below 62% across all iterations.
* The "Multi-hop" and "Temporal" categories show similar performance levels, fluctuating between approximately 73% and 76%.
* All categories show a slight positive trend in performance as the number of iterations increases, although the effect is more pronounced for "Open-domain".
### Interpretation
The data suggests that the LLM-as-a-judge performs best on "Single-hop" tasks and least well on "Open-domain" tasks. The increase in performance with more iterations indicates that allowing the LLM more opportunities to refine its judgment improves accuracy, particularly for more complex tasks like "Open-domain". The relatively stable performance of "Single-hop" suggests that these tasks are easily judged even with a limited number of iterations. The slight improvements observed across all categories with increasing iterations suggest that iterative refinement is a generally beneficial strategy for LLM-based judgment. The difference in performance between the categories likely reflects the inherent difficulty of each task type, with "Open-domain" requiring more nuanced reasoning and knowledge than "Single-hop".