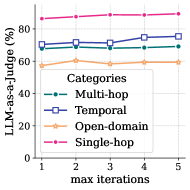
## Line Chart: LLM-as-a-Judge Performance Across Task Categories
### Overview
The image is a line chart displaying the performance (as a percentage) of an "LLM-as-a-judge" system across four different task categories, measured over a series of increasing "max iterations." The chart plots performance on the y-axis against the number of iterations on the x-axis.
### Components/Axes
* **Chart Type:** Multi-series line chart with markers.
* **X-Axis:**
* **Label:** `max iterations`
* **Scale:** Linear, with integer markers from 1 to 5.
* **Y-Axis:**
* **Label:** `LLM-as-a-judge (%)`
* **Scale:** Linear, ranging from 50 to 90, with major gridlines at intervals of 10 (50, 60, 70, 80, 90).
* **Legend:**
* **Position:** Center-right of the chart area, slightly overlapping the data lines.
* **Title:** `Categories`
* **Items (from top to bottom as listed in legend):**
1. **Multi-hop:** Blue line with circular markers.
2. **Temporal:** Orange line with square markers.
3. **Open-domain:** Green line with diamond markers.
4. **Single-hop:** Pink/magenta line with triangular markers.
### Detailed Analysis
Data points are approximate, read from the chart's grid.
**1. Single-hop (Pink line, triangles):**
* **Trend:** Consistently the highest-performing category. Shows a very slight, steady upward trend across all iterations.
* **Approximate Values:**
* Iteration 1: ~85%
* Iteration 2: ~86%
* Iteration 3: ~87%
* Iteration 4: ~88%
* Iteration 5: ~89%
**2. Multi-hop (Blue line, circles):**
* **Trend:** Starts as the second-highest. Dips slightly at iteration 2, then recovers and shows a moderate upward trend from iteration 3 onward.
* **Approximate Values:**
* Iteration 1: ~70%
* Iteration 2: ~68% (dip)
* Iteration 3: ~70%
* Iteration 4: ~73%
* Iteration 5: ~75%
**3. Temporal (Orange line, squares):**
* **Trend:** Starts as the third-highest. Shows a slight peak at iteration 3 before declining slightly.
* **Approximate Values:**
* Iteration 1: ~60%
* Iteration 2: ~62%
* Iteration 3: ~65% (peak)
* Iteration 4: ~63%
* Iteration 5: ~62%
**4. Open-domain (Green line, diamonds):**
* **Trend:** The lowest-performing category overall. Performance is relatively flat with minor fluctuations, showing a slight dip at iteration 4.
* **Approximate Values:**
* Iteration 1: ~58%
* Iteration 2: ~59%
* Iteration 3: ~58%
* Iteration 4: ~56% (dip)
* Iteration 5: ~58%
### Key Observations
1. **Clear Performance Hierarchy:** There is a distinct and consistent separation between the performance levels of the four task categories. `Single-hop` > `Multi-hop` > `Temporal` ≈ `Open-domain`.
2. **Divergent Trends with Iterations:** The categories respond differently to increased iterations:
* `Single-hop` and `Multi-hop` show net positive trends.
* `Temporal` shows a non-monotonic trend (rise then fall).
* `Open-domain` shows no clear positive or negative trend.
3. **Stability vs. Change:** `Single-hop` performance is both high and stable. `Multi-hop` shows the most significant positive change. `Temporal` and `Open-domain` are lower and exhibit more volatility without clear improvement.
4. **No Convergence:** The lines do not converge as iterations increase; the performance gap between the best (`Single-hop`) and worst (`Open-domain`) categories remains large (~30 percentage points).
### Interpretation
This chart likely evaluates how the reliability or accuracy of using a Large Language Model (LLM) as an automated judge changes when it is allowed more iterative attempts (`max iterations`) for different types of reasoning tasks.
* **Task Complexity Correlates with Performance:** The data strongly suggests that the LLM judge finds `Single-hop` tasks (simple, direct reasoning) easiest, achieving near 90% performance. `Multi-hop` tasks (requiring chained reasoning) are significantly harder. `Temporal` (time-based reasoning) and `Open-domain` (broad, unstructured knowledge) tasks appear to be the most challenging for the judge, hovering around 60%.
* **Effect of Iterative Refinement:** Giving the LLM judge more iterations helps most for `Multi-hop` tasks, suggesting that complex reasoning benefits from repeated evaluation or self-correction. The benefit for `Single-hop` tasks is marginal, likely because performance is already near a ceiling. The lack of improvement for `Temporal` and `Open-domain` tasks indicates that simply repeating the judgment process does not overcome the fundamental difficulty the model has with these domains; the errors may be systematic rather than stochastic.
* **Practical Implication:** If one is building a system that uses an LLM to evaluate other models' outputs, this chart indicates that the judge's scores will be highly dependent on the *type* of task being evaluated. One cannot assume a consistent level of judge reliability across different domains. For critical applications involving temporal or open-domain reasoning, human oversight or alternative evaluation methods would be necessary, as the LLM judge's performance is relatively low and does not improve with more computational effort (iterations).