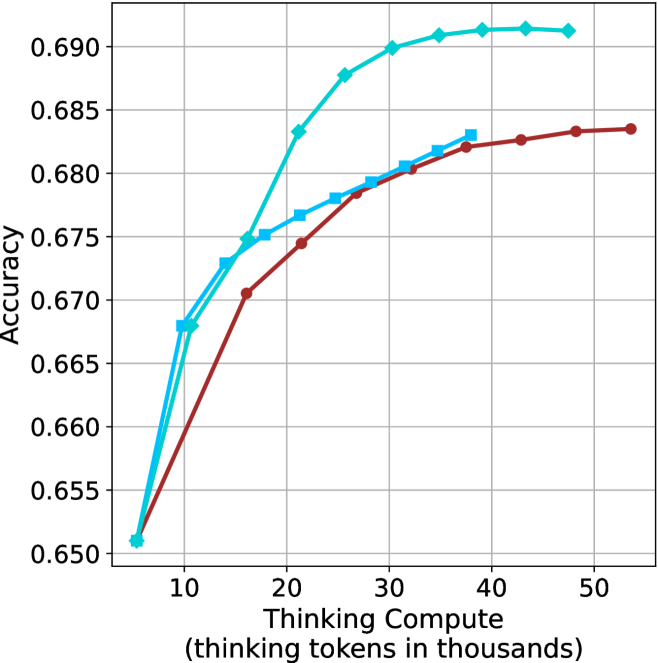
## Line Graph: Model Accuracy vs. Thinking Compute
### Overview
The image depicts a line graph comparing the accuracy of two models (Model A and Model B) as a function of "Thinking Compute" (measured in thousands of thinking tokens). Both models show increasing accuracy with higher compute, but Model A consistently outperforms Model B across all compute levels.
### Components/Axes
- **X-axis**: "Thinking Compute (thinking tokens in thousands)"
- Scale: 10 to 50 (in increments of 10)
- **Y-axis**: "Accuracy"
- Scale: 0.650 to 0.690 (in increments of 0.005)
- **Legend**: Located in the top-right corner
- Blue line: Model A
- Red line: Model B
### Detailed Analysis
#### Model A (Blue Line)
- **Data Points**:
- 10k tokens: 0.665
- 20k tokens: 0.675
- 30k tokens: 0.685
- 40k tokens: 0.690
- 50k tokens: 0.690
- **Trend**: Steep initial increase (10k–30k tokens), plateauing at 0.690 after 30k tokens.
#### Model B (Red Line)
- **Data Points**:
- 10k tokens: 0.650
- 20k tokens: 0.670
- 30k tokens: 0.680
- 40k tokens: 0.685
- 50k tokens: 0.685
- **Trend**: Gradual, linear growth with diminishing returns after 30k tokens.
### Key Observations
1. **Model A** achieves higher accuracy at all compute levels, with a maximum accuracy of 0.690 (vs. 0.685 for Model B).
2. **Efficiency**: Model A reaches its peak accuracy (0.690) at 30k tokens, while Model B requires 40k tokens to reach 0.685.
3. **Diminishing Returns**: Both models plateau after 30k–40k tokens, suggesting limited gains from additional compute.
4. **Initial Advantage**: Model A starts with a 0.015 accuracy lead at 10k tokens, widening to 0.010 at 50k tokens.
### Interpretation
The data suggests **Model A is more efficient**, achieving higher accuracy with fewer compute resources. The steeper slope of Model A’s curve indicates faster scaling, while its plateau at 30k tokens implies a potential architectural or algorithmic advantage. Model B’s slower growth and lower ceiling may reflect suboptimal design or training constraints. The diminishing returns for both models highlight a practical limit to compute-driven accuracy improvements, emphasizing the need for architectural innovation over brute-force scaling.