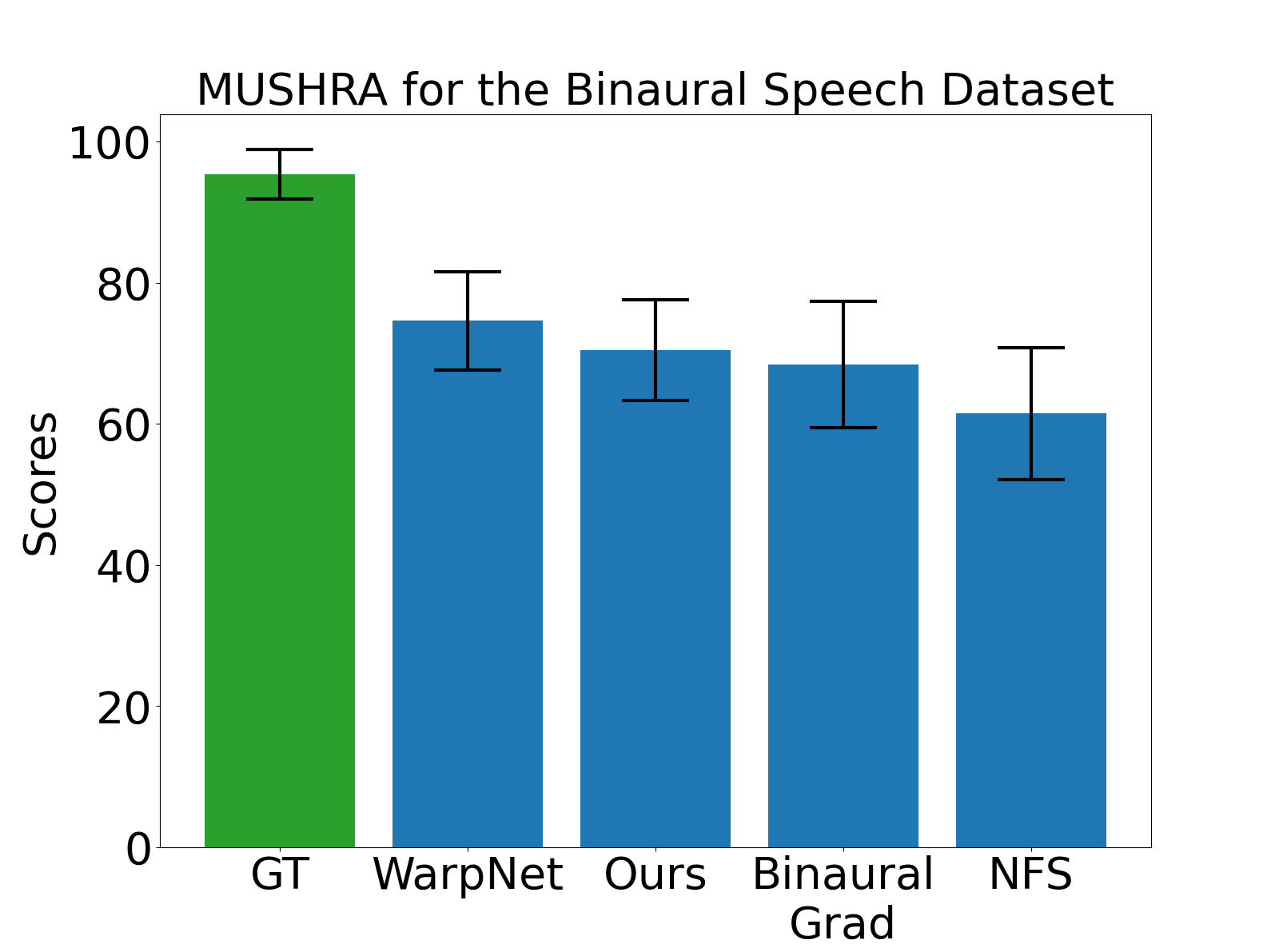
## Bar Chart: MUSHRA for the Binaural Speech Dataset
### Overview
The chart compares MUSHRA (Multidimensional Subjective With Reference Test) scores for five categories: GT (Ground Truth), WarpNet, Ours, Binaural Grad, and NFS. Scores range from 0 to 100, with error bars indicating variability.
### Components/Axes
- **X-axis**: Categories (GT, WarpNet, Ours, Binaural Grad, NFS)
- **Y-axis**: Scores (0–100)
- **Legend**:
- Green: GT
- Blue: WarpNet, Ours, Binaural Grad, NFS
- **Error Bars**: Black, positioned above each bar
### Detailed Analysis
1. **GT (Ground Truth)**:
- Score: ~95 (highest)
- Error: ±3 (smallest variability)
2. **WarpNet**:
- Score: ~75
- Error: ±5
3. **Ours**:
- Score: ~70
- Error: ±4
4. **Binaural Grad**:
- Score: ~68
- Error: ±6
5. **NFS**:
- Score: ~60
- Error: ±7 (largest variability)
### Key Observations
- GT scores significantly higher than all other categories.
- WarpNet and Ours show moderate performance, with WarpNet slightly outperforming Ours.
- Binaural Grad and NFS have lower scores, with NFS exhibiting the greatest variability.
- Error bars suggest increasing uncertainty in scores from GT to NFS.
### Interpretation
The data demonstrates that GT (Ground Truth) achieves the highest MUSHRA scores, reflecting its role as the reference standard. The models (WarpNet, Ours, Binaural Grad, NFS) perform progressively worse compared to GT, with NFS showing the least consistency. The error bars highlight that variability in scores increases as models deviate from the ground truth, suggesting potential challenges in replicating human-like performance in binaural speech processing. The term "Ours" likely refers to the authors' proposed model, which outperforms other non-GT methods but still lags behind the reference.