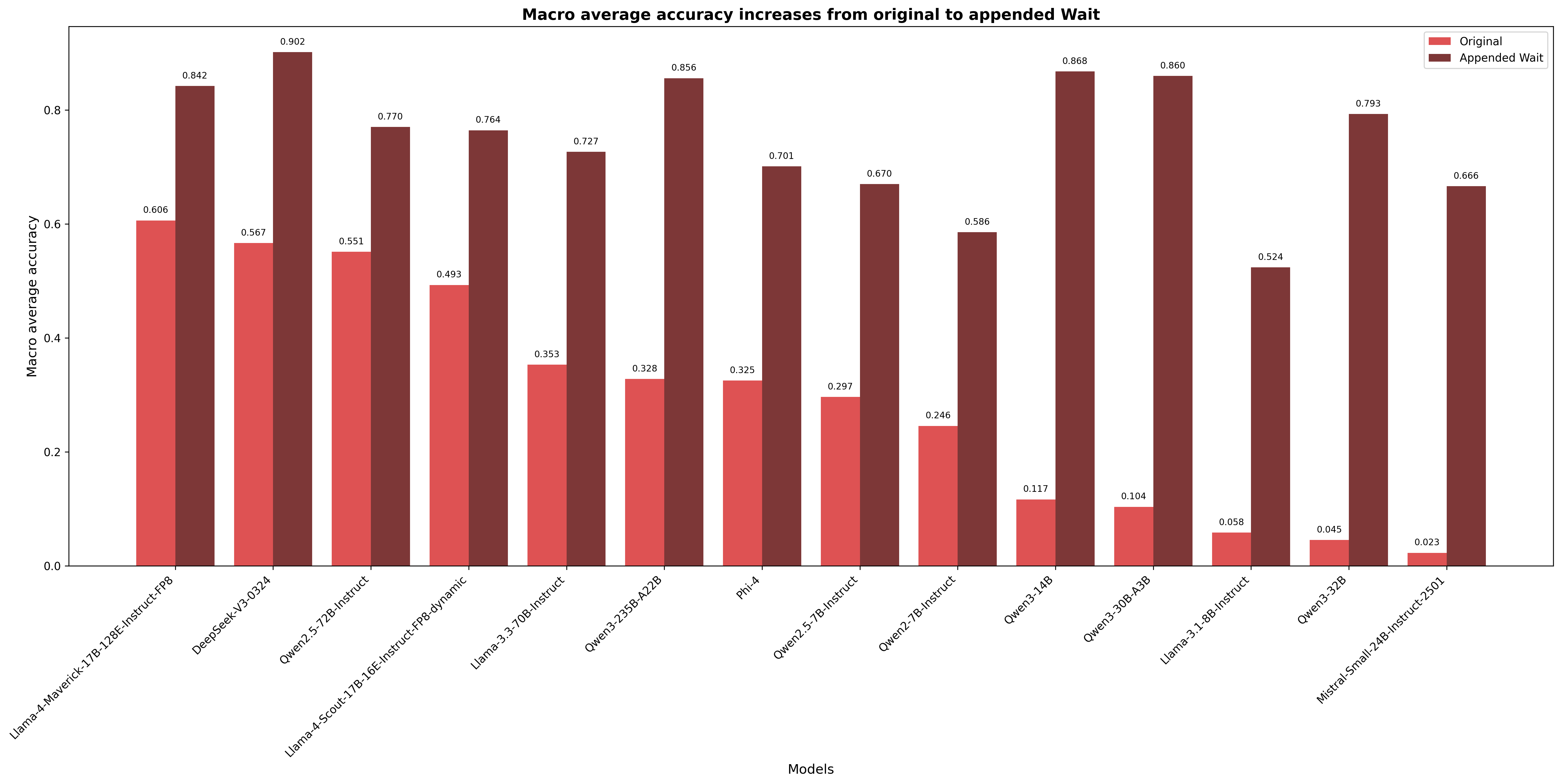
## Bar Chart: Macro Average Accuracy Comparison (Original vs. Appended Wait)
### Overview
This is a grouped bar chart comparing the macro average accuracy of 14 different large language models under two conditions: "Original" and "Appended Wait." The chart demonstrates a consistent and significant increase in accuracy for every model when the "Wait" condition is applied.
### Components/Axes
* **Title:** "Macro average accuracy increases from original to appended Wait" (centered at the top).
* **Y-Axis:** Labeled "Macro average accuracy." The scale runs from 0.0 to 0.8 with major tick marks at 0.0, 0.2, 0.4, 0.6, and 0.8.
* **X-Axis:** Labeled "Models." It lists 14 distinct model names, rotated for readability.
* **Legend:** Located in the top-right corner. It defines two data series:
* **Original:** Represented by red/coral-colored bars.
* **Appended Wait:** Represented by dark brown/maroon-colored bars.
* **Data Labels:** Each bar has its exact numerical value displayed directly above it.
### Detailed Analysis
The chart presents paired data for each model. The "Appended Wait" bar is taller than the "Original" bar in every single case.
**Model-by-Model Data Extraction (Original, Appended Wait):**
| Model | Original | Appended Wait |
| :--- | :--- | :--- |
| Llama-4-Maverick-17B-128E-Instruct-FP8 | 0.606 | 0.842 |
| DeepSeek-V3-0324 | 0.567 | 0.902 |
| Qwen2.5-72B-Instruct | 0.551 | 0.770 |
| Llama-4-Scout-17B-16E-Instruct-FP8-dynamic | 0.493 | 0.764 |
| Llama-3.3-70B-Instruct | 0.353 | 0.727 |
| Qwen3-235B-A22B | 0.328 | 0.856 |
| Phi-4 | 0.325 | 0.701 |
| Qwen2.5-7B-Instruct | 0.297 | 0.670 |
| Qwen2-7B-Instruct | 0.246 | 0.586 |
| Qwen3-14B | 0.117 | 0.868 |
| Qwen3-30B-A3B | 0.104 | 0.860 |
| Llama-3.1-8B-Instruct | 0.058 | 0.524 |
| Qwen3-32B | 0.045 | 0.793 |
| Mistral-Small-24B-Instruct-2501 | 0.023 | 0.666 |
### Key Observations
1. **Universal Improvement:** All 14 models show a higher macro average accuracy in the "Appended Wait" condition compared to the "Original" condition.
2. **Magnitude of Increase:** The improvement is substantial. The smallest absolute increase is approximately +0.236 (Llama-4-Maverick), while the largest is approximately +0.751 (Qwen3-14B).
3. **Performance Reversal:** Models with very low original accuracy (e.g., Qwen3-14B at 0.117, Qwen3-32B at 0.045) often achieve some of the highest accuracies in the "Appended Wait" condition (0.868 and 0.793, respectively), suggesting the intervention is particularly effective for these models.
4. **Top Performers:** In the "Appended Wait" condition, the highest accuracy is achieved by DeepSeek-V3-0324 (0.902), followed closely by Qwen3-14B (0.868) and Qwen3-30B-A3B (0.860).
### Interpretation
The data provides strong, consistent evidence that the "Appended Wait" technique or condition significantly boosts the macro average accuracy of the evaluated language models. The effect is not marginal; it transforms performance, especially for models that initially performed poorly.
This suggests that the "Wait" mechanism likely addresses a fundamental limitation in the models' original inference or reasoning process. It could be implementing a form of "chain-of-thought" prompting, a deliberate pause for computation, or a correction step that allows models to self-verify or refine their outputs before finalizing them. The dramatic gains for lower-performing models indicate that this mechanism may help overcome specific failure modes or instabilities in their base architecture or training. The chart effectively argues for the "Appended Wait" method as a highly reliable and impactful enhancement for a wide variety of model architectures and sizes.