## Bar Chart: Macro average accuracy increases from original to appended Wait
### Overview
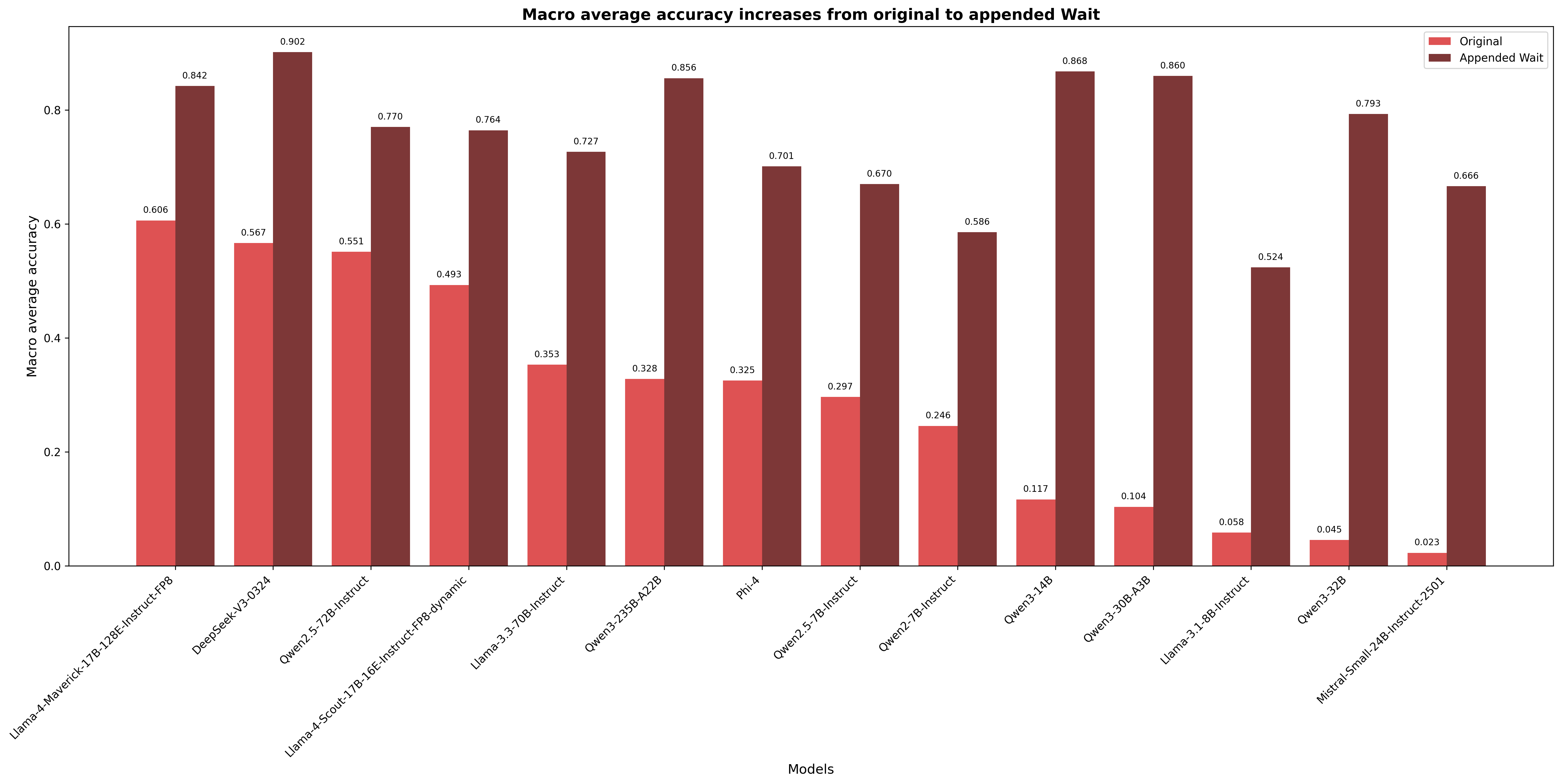
The chart compares macro average accuracy values between "Original" and "Appended Wait" configurations across 14 different AI models. Two data series are shown: red bars for Original accuracy and dark red bars for Appended Wait accuracy. The y-axis ranges from 0.0 to 0.9, while the x-axis lists model names in descending order of Appended Wait performance.
### Components/Axes
- **X-axis**: Model names (categorical)
- Llama-4-Maverick-17B-128E-Instruct-FP8
- DeepSeek-V3-0324
- Gwen2.5-72B-Instruct
- Llama-4-Scout-17B-Instruct-FP8-dynamic
- Llama-3-3-70B-Instruct
- Owen3-235B-A22B
- Phi-4
- Owen2.5-7B-Instruct
- Owen2.7B-Instruct
- Owen3-3-14B
- Owen3-30B-A3B
- Llama-3-1-8B-Instruct
- Owen3-32B
- Mistral-Small-24B-Instruct-2501
- **Y-axis**: Macro average accuracy (0.0 to 0.9)
- **Legend**:
- Red = Original
- Dark red = Appended Wait
- **Title**: Macro average accuracy increases from original to appended Wait
### Detailed Analysis
| Model Name | Original Accuracy | Appended Wait Accuracy |
|------------|-------------------|------------------------|
| Llama-4-Maverick-17B-128E-Instruct-FP8 | 0.606 | 0.842 |
| DeepSeek-V3-0324 | 0.567 | 0.902 |
| Gwen2.5-72B-Instruct | 0.551 | 0.770 |
| Llama-4-Scout-17B-Instruct-FP8-dynamic | 0.493 | 0.764 |
| Llama-3-3-70B-Instruct | 0.353 | 0.727 |
| Owen3-235B-A22B | 0.328 | 0.856 |
| Phi-4 | 0.325 | 0.701 |
| Owen2.5-7B-Instruct | 0.297 | 0.670 |
| Owen2.7B-Instruct | 0.246 | 0.586 |
| Owen3-3-14B | 0.117 | 0.868 |
| Owen3-30B-A3B | 0.104 | 0.860 |
| Llama-3-1-8B-Instruct | 0.058 | 0.524 |
| Owen3-32B | 0.045 | 0.793 |
| Mistral-Small-24B-Instruct-2501 | 0.023 | 0.666 |
### Key Observations
1. **General Trend**: Appended Wait configurations consistently outperform Original across all models (median increase: +0.283)
2. **Highest Performers**:
- DeepSeek-V3-0324 shows the largest improvement (+0.335)
- Owen3-3-14B and Owen3-30B-A3B both achieve >0.85 Appended Wait accuracy
3. **Lowest Performers**:
- Mistral-Small-24B-Instruct-2501 has the lowest Original accuracy (0.023)
- Llama-3-1-8B-Instruct shows the smallest improvement (+0.466)
4. **Notable Outliers**:
- Owen2.7B-Instruct (0.246 → 0.586) demonstrates significant relative improvement
- Phi-4 (0.325 → 0.701) shows moderate gains despite mid-range Original performance
### Interpretation
The data suggests that appending Wait configurations significantly enhances model performance across diverse architectures. The most dramatic improvements occur in models with initially lower Original accuracy (e.g., Mistral-Small-24B-Instruct-2501: +0.643 increase). However, the relationship between model size and improvement isn't strictly linear - smaller models like Llama-3-1-8B-Instruct show substantial gains despite lower base performance. The consistent pattern of Appended Wait outperforming Original indicates that Wait augmentation provides a reliable performance boost, though the magnitude varies by model architecture and configuration. The chart highlights the importance of Wait optimization in achieving high macro average accuracy, particularly for models with initially weaker performance.