## Bar Chart: Model Accuracy Comparison
### Overview
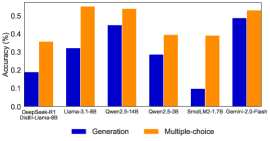
The chart compares the accuracy of six AI models (DeepSeek-R1, Llama-3-1-8B, Qwen2.5-14B, Qwen2.5-3B, SmolLM2-1.7B, Gemini-2.0-Flash) across two tasks: **Generation** (blue bars) and **Multiple-choice** (orange bars). Accuracy is measured in percentage, with values ranging from 0% to 0.5% on the y-axis.
### Components/Axes
- **X-axis**: Model names (DeepSeek-R1, Llama-3-1-8B, Qwen2.5-14B, Qwen2.5-3B, SmolLM2-1.7B, Gemini-2.0-Flash).
- **Y-axis**: Accuracy (%) from 0.0 to 0.5, with increments of 0.1.
- **Legend**:
- Blue = Generation
- Orange = Multiple-choice
- **Bar Placement**: Paired bars (Generation and Multiple-choice) are centered under each model label.
### Detailed Analysis
- **DeepSeek-R1**:
- Generation: ~0.2%
- Multiple-choice: ~0.35%
- **Llama-3-1-8B**:
- Generation: ~0.32%
- Multiple-choice: ~0.55%
- **Qwen2.5-14B**:
- Generation: ~0.45%
- Multiple-choice: ~0.53%
- **Qwen2.5-3B**:
- Generation: ~0.29%
- Multiple-choice: ~0.40%
- **SmolLM2-1.7B**:
- Generation: ~0.10%
- Multiple-choice: ~0.40%
- **Gemini-2.0-Flash**:
- Generation: ~0.49%
- Multiple-choice: ~0.53%
### Key Observations
1. **Multiple-choice tasks consistently outperform Generation tasks** across all models (e.g., Llama-3-1-8B: 0.55% vs. 0.32%).
2. **Qwen2.5-14B** achieves the highest accuracy in both tasks (~0.45% Generation, ~0.53% Multiple-choice).
3. **SmolLM2-1.7B** has the lowest Generation accuracy (~0.10%), despite matching Qwen2.5-3B in Multiple-choice.
4. **Gemini-2.0-Flash** performs strongly in both tasks (~0.49% Generation, ~0.53% Multiple-choice), suggesting efficiency.
### Interpretation
The data suggests that **Multiple-choice tasks are inherently easier for these models**, likely due to structured answer formats reducing ambiguity. Larger models (e.g., Qwen2.5-14B, Gemini-2.0-Flash) generally excel, but smaller models like SmolLM2-1.7B underperform in Generation, indicating that model size alone does not guarantee task proficiency. The narrow gap between Generation and Multiple-choice accuracy for Gemini-2.0-Flash highlights its robustness in handling open-ended tasks.