\n
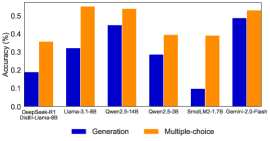
## Bar Chart: Accuracy Comparison of Language Models
### Overview
This image presents a bar chart comparing the accuracy of several language models on two different task types: "Generation" and "Multiple-choice". The chart uses paired bars for each model, with blue representing "Generation" accuracy and orange representing "Multiple-choice" accuracy. The x-axis lists the model names, and the y-axis represents accuracy as a percentage.
### Components/Axes
* **X-axis:** Model Names: DeepSeek-R1, Llama-3.1-6B, Qwen-2.5-14B, Qwen-2.5-3B, SmalLM2-1.7B, Gemini-2.0-Flash. The label "Dweil-Llama-8B" is present under "DeepSeek-R1" but appears to be a footnote or related information.
* **Y-axis:** Accuracy (%) - Scale ranges from 0.0 to 0.6, with increments of 0.1.
* **Legend:** Located at the bottom-center of the chart.
* Blue: Generation
* Orange: Multiple-choice
### Detailed Analysis
Let's analyze each model's performance, starting from left to right:
1. **DeepSeek-R1:**
* Generation (Blue): Approximately 0.18 (±0.02)
* Multiple-choice (Orange): Approximately 0.34 (±0.02)
2. **Llama-3.1-6B:**
* Generation (Blue): Approximately 0.32 (±0.02)
* Multiple-choice (Orange): Approximately 0.54 (±0.02)
3. **Qwen-2.5-14B:**
* Generation (Blue): Approximately 0.44 (±0.02)
* Multiple-choice (Orange): Approximately 0.54 (±0.02)
4. **Qwen-2.5-3B:**
* Generation (Blue): Approximately 0.28 (±0.02)
* Multiple-choice (Orange): Approximately 0.38 (±0.02)
5. **SmalLM2-1.7B:**
* Generation (Blue): Approximately 0.09 (±0.02)
* Multiple-choice (Orange): Approximately 0.38 (±0.02)
6. **Gemini-2.0-Flash:**
* Generation (Blue): Approximately 0.48 (±0.02)
* Multiple-choice (Orange): Approximately 0.51 (±0.02)
**Trends:**
* For most models, the Multiple-choice accuracy is higher than the Generation accuracy.
* The Generation accuracy varies significantly across models.
* The Multiple-choice accuracy is relatively consistent across models, generally falling between 0.34 and 0.54.
### Key Observations
* SmalLM2-1.7B exhibits particularly low Generation accuracy (around 0.09).
* Gemini-2.0-Flash shows the highest Generation accuracy (around 0.48).
* Llama-3.1-6B has a large difference between its Generation and Multiple-choice accuracy.
* Qwen-2.5-14B and Gemini-2.0-Flash have similar performance on both tasks.
### Interpretation
The chart demonstrates that the performance of these language models varies significantly depending on the task type. Multiple-choice tasks generally yield higher accuracy scores than generation tasks. This suggests that these models are better at selecting the correct answer from a given set of options than they are at creating novel text. The wide range of Generation accuracy scores indicates that some models are more capable of generating coherent and accurate text than others. The relatively consistent Multiple-choice accuracy suggests that this task is less sensitive to model architecture or training data. The outlier, SmalLM2-1.7B, performs poorly on Generation, indicating a potential weakness in its generative capabilities. The difference between Generation and Multiple-choice accuracy for Llama-3.1-6B could indicate a bias in its training data or a limitation in its ability to generalize to open-ended tasks. The chart provides valuable insights into the strengths and weaknesses of different language models, which can inform model selection for specific applications.