## Bar Chart: E-CARE: Avg. Proof Depth
### Overview
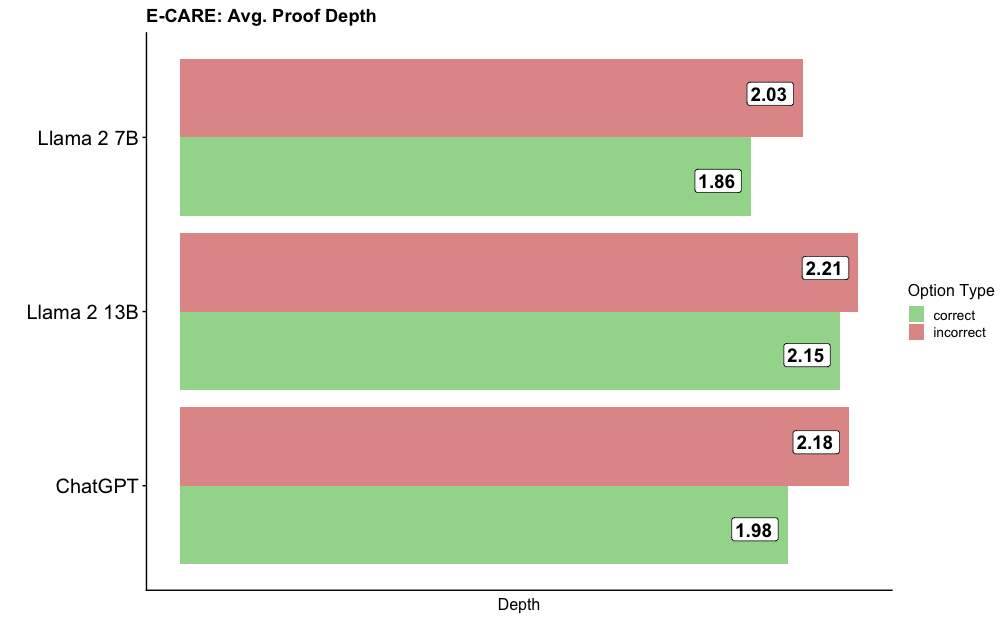
The chart compares the average proof depth for three language models (Llama 2 7B, Llama 2 13B, and ChatGPT) across two categories: "correct" (green) and "incorrect" (red) options. The x-axis represents "Depth," while the y-axis lists the models. Numerical values are embedded in the bars, with green bars showing lower depths for correct answers and red bars showing higher depths for incorrect answers.
### Components/Axes
- **Title**: "E-CARE: Avg. Proof Depth"
- **Y-Axis (Categories)**:
- Llama 2 7B
- Llama 2 13B
- ChatGPT
- **X-Axis (Scale)**: Labeled "Depth" (numerical values from ~1.8 to 2.2).
- **Legend**:
- Green: "correct"
- Red: "incorrect"
- **Bar Structure**:
- Each model has two bars (green for correct, red for incorrect).
- Values are placed on top of the bars (e.g., "1.86" for Llama 2 7B correct).
### Detailed Analysis
- **Llama 2 7B**:
- Correct: 1.86 (green)
- Incorrect: 2.03 (red)
- **Llama 2 13B**:
- Correct: 2.15 (green)
- Incorrect: 2.21 (red)
- **ChatGPT**:
- Correct: 1.98 (green)
- Incorrect: 2.18 (red)
### Key Observations
1. **Incorrect depths exceed correct depths** for all models, indicating higher average proof depth for incorrect answers.
2. **Llama 2 13B** has the highest incorrect depth (2.21) but also the highest correct depth (2.15), suggesting it performs better on correct answers despite higher incorrect depths.
3. **ChatGPT** has the lowest correct depth (1.98) and the second-highest incorrect depth (2.18), indicating moderate performance.
4. **Llama 2 7B** has the lowest correct depth (1.86) and the lowest incorrect depth (2.03), suggesting it struggles more with correct answers but performs better on incorrect ones.
### Interpretation
The data suggests that larger models (e.g., Llama 2 13B) may have higher proof depths for both correct and incorrect answers, potentially due to increased complexity in reasoning. However, Llama 2 13B's higher correct depth (2.15) compared to its incorrect depth (2.21) implies it is more accurate in its reasoning. ChatGPT's performance is intermediate, with a lower correct depth but higher incorrect depth than Llama 2 7B. The chart highlights a trade-off between model size and accuracy, with larger models excelling in correct answers but also showing higher variability in incorrect responses. The values are approximate, and the trends align with the visual representation of bar lengths.