# Technical Data Extraction: Model Safety Performance Comparison
## 1. Image Overview
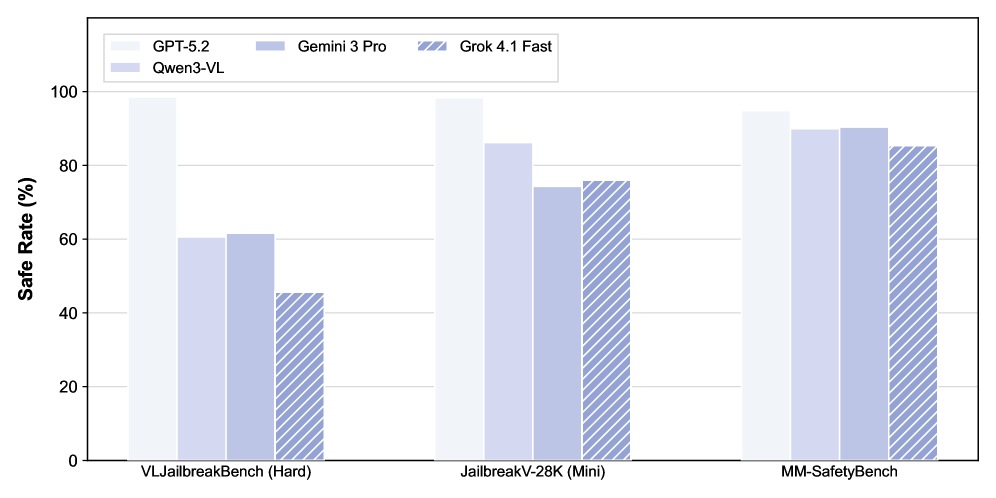
This image is a grouped bar chart comparing the "Safe Rate (%)" of four different Large Language Models (LLMs) across three specific safety benchmarks. The chart uses a blue-toned color palette and patterns to distinguish between the models.
## 2. Component Isolation
### Header / Legend
* **Location:** Top-left quadrant, within the chart area boundaries.
* **Legend Items (Left to Right):**
1. **GPT-5.2**: Represented by a very light, near-white blue solid bar.
2. **Qwen3-VL**: Represented by a light lavender/blue solid bar.
3. **Gemini 3 Pro**: Represented by a medium-light blue solid bar.
4. **Grok 4.1 Fast**: Represented by a medium blue bar with white diagonal hatching (slanted lines).
### Main Chart Area
* **Y-Axis Label:** "Safe Rate (%)" (Oriented vertically).
* **Y-Axis Scale:** 0 to 100, with major gridlines and markers every 20 units (0, 20, 40, 60, 80, 100).
* **X-Axis Categories (Benchmarks):**
1. **VLJailbreakBench (Hard)**
2. **JailbreakV-28K (Mini)**
3. **MM-SafetyBench**
## 3. Data Extraction and Trend Analysis
### Trend Verification
* **GPT-5.2 (Near-white):** Maintains the highest safety rate across all benchmarks, consistently staying near the 100% mark.
* **Qwen3-VL (Light lavender):** Shows significant improvement as the benchmarks change, starting at ~60% and rising to ~90%.
* **Gemini 3 Pro (Medium-light blue):** Shows a steady upward trend across the three benchmarks.
* **Grok 4.1 Fast (Hatched):** Shows the most dramatic upward trend, starting as the lowest performer in the first benchmark and rising significantly in the subsequent two.
### Reconstructed Data Table (Estimated Values)
Values are extracted based on visual alignment with the Y-axis gridlines.
| Benchmark | GPT-5.2 | Qwen3-VL | Gemini 3 Pro | Grok 4.1 Fast |
| :--- | :---: | :---: | :---: | :---: |
| **VLJailbreakBench (Hard)** | ~98% | ~60% | ~61% | ~45% |
| **JailbreakV-28K (Mini)** | ~98% | ~86% | ~74% | ~76% |
| **MM-SafetyBench** | ~95% | ~90% | ~90% | ~85% |
## 4. Detailed Component Analysis
### VLJailbreakBench (Hard)
In this "Hard" benchmark, there is a wide disparity in performance. GPT-5.2 is the clear leader, nearly reaching 100%. Qwen3-VL and Gemini 3 Pro perform similarly, hovering around the 60% mark. Grok 4.1 Fast performs the poorest here, falling below 50%.
### JailbreakV-28K (Mini)
Performance improves for all models except GPT-5.2, which remains stable. Qwen3-VL sees a significant jump to approximately 86%. Gemini 3 Pro and Grok 4.1 Fast are closely matched in the mid-70s range.
### MM-SafetyBench
This benchmark shows the highest level of parity between the models. While GPT-5.2 still leads (slightly lower than previous benchmarks at ~95%), Qwen3-VL and Gemini 3 Pro have converged at approximately 90%. Grok 4.1 Fast reaches its peak performance here at approximately 85%.
## 5. Language Declaration
The text in this image is entirely in **English**. No other languages are present.