\n
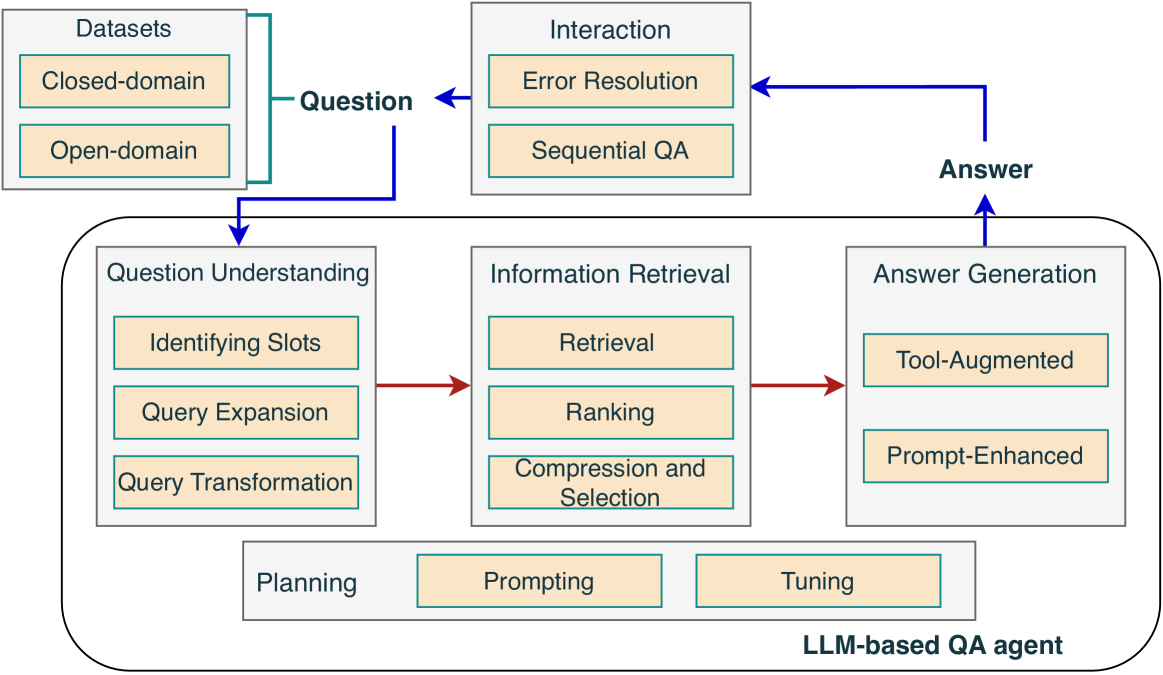
## Diagram: LLM-based QA Agent System Architecture
### Overview
This image is a technical system architecture diagram illustrating the components and workflow of a Large Language Model (LLM)-based Question Answering (QA) agent. It depicts how a question is processed through various stages, from understanding to answer generation, and includes feedback loops for interaction and planning.
### Components/Axes
The diagram is organized into three primary sections, with a central, large rounded rectangle representing the core agent.
1. **Top-Left: Datasets**
* A gray box labeled "Datasets".
* Contains two beige sub-boxes: "Closed-domain" and "Open-domain".
* A blue arrow labeled "Question" originates from this box and points towards the central agent.
2. **Top-Right: Interaction**
* A gray box labeled "Interaction".
* Contains two beige sub-boxes: "Error Resolution" and "Sequential QA".
* A blue arrow labeled "Answer" points into this box from the central agent.
* A blue arrow originates from this box and points back to the "Question" arrow, creating a feedback loop.
3. **Center: LLM-based QA agent**
* A large, rounded gray rectangle labeled "LLM-based QA agent" at its bottom-right corner.
* Contains three main processing blocks and one supporting block:
* **Question Understanding (Left Block):** A gray box containing three beige sub-boxes: "Identifying Slots", "Query Expansion", and "Query Transformation".
* **Information Retrieval (Center Block):** A gray box containing three beige sub-boxes: "Retrieval", "Ranking", and "Compression and Selection".
* **Answer Generation (Right Block):** A gray box containing two beige sub-boxes: "Tool-Augmented" and "Prompt-Enhanced".
* **Planning (Bottom Block):** A gray box containing two beige sub-boxes: "Prompting" and "Tuning".
### Detailed Analysis
**Flow and Connections:**
* The primary data flow is indicated by **blue arrows**. A "Question" enters from the Datasets, is processed by the agent, and an "Answer" is output to the Interaction module. The Interaction module can then feed back into the question pipeline.
* The internal processing flow within the agent is indicated by **red arrows**. The sequence is: `Question Understanding` -> `Information Retrieval` -> `Answer Generation`.
* The "Planning" block is positioned below the three main processing blocks but is not connected by arrows, suggesting it is a foundational or supporting component for the entire agent.
**Component Details:**
* **Question Understanding:** This stage breaks down the incoming question. Sub-tasks include identifying key slots (parameters/entities), expanding the query for better search, and transforming it into an optimal format.
* **Information Retrieval:** This stage finds relevant information. It involves retrieving documents or data, ranking them by relevance, and then compressing or selecting the most pertinent information.
* **Answer Generation:** This stage formulates the final answer. It can be "Tool-Augmented" (using external tools or APIs) or "Prompt-Enhanced" (using advanced prompting techniques with the LLM).
* **Interaction:** This module handles post-generation steps, including resolving errors in the answer and managing multi-turn, sequential Q&A sessions.
* **Planning:** This component involves "Prompting" (designing effective instructions for the LLM) and "Tuning" (potentially fine-tuning the model), which are strategic activities that inform the agent's operation.
### Key Observations
1. **Cyclical Process:** The diagram explicitly shows a feedback loop from the "Answer" back through "Interaction" to the "Question," indicating an iterative or conversational QA process, not a single-turn system.
2. **Modular Design:** The agent's core functions are clearly separated into distinct, sequential modules (Understanding -> Retrieval -> Generation), which is a common architectural pattern for complex AI systems.
3. **Supporting vs. Core Flow:** The "Planning" block is visually separate from the main red-arrow flow, highlighting its role as a meta-component that configures or optimizes the core pipeline rather than processing individual questions directly.
4. **Input Diversity:** The system is designed to handle questions from both "Closed-domain" (specific, restricted knowledge) and "Open-domain" (general, wide-ranging) datasets.
### Interpretation
This diagram represents a sophisticated, production-oriented QA system architecture. It moves beyond a simple "input question -> LLM -> output answer" model by incorporating several critical real-world components:
* **Robustness:** The "Interaction" module with "Error Resolution" acknowledges that initial answers may be flawed and need correction, either automatically or via user feedback.
* **Retrieval-Augmented Generation (RAG):** The dedicated "Information Retrieval" block strongly suggests this is a RAG system, where the LLM's knowledge is augmented by fetching relevant documents from external datasets before generating an answer. This is key for accuracy and reducing hallucinations.
* **System Optimization:** The inclusion of "Planning" with "Tuning" indicates this is not a static model but one that can be improved over time through techniques like fine-tuning or prompt optimization.
* **Complexity Management:** The separation into "Identifying Slots," "Query Expansion," etc., shows an understanding that effective QA requires significant pre-processing of the natural language question to bridge the gap between human language and structured information retrieval.
In essence, the diagram illustrates a comprehensive framework for building a reliable, interactive, and maintainable QA agent that leverages both internal LLM capabilities and external data sources.