# Technical Analysis: Mixture-of-Depths Architecture and Routing Comparisons
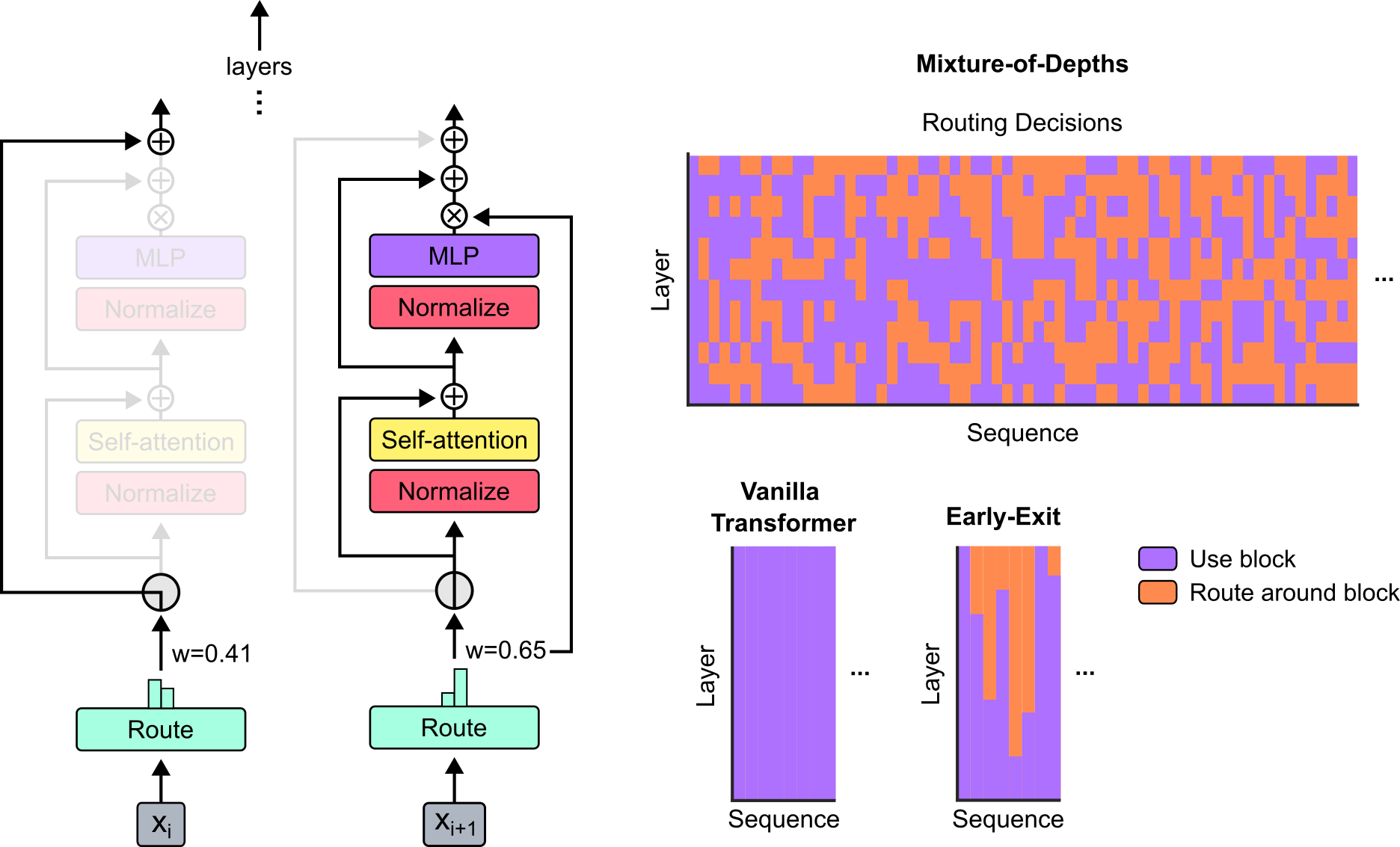
This document provides a detailed technical extraction of the provided image, which illustrates the architecture of a "Mixture-of-Depths" (MoD) neural network and compares its routing decisions against "Vanilla Transformer" and "Early-Exit" models.
---
## 1. Architectural Diagram (Left Side)
The left portion of the image depicts the internal flow of two consecutive tokens, $x_i$ and $x_{i+1}$, through a transformer-like layer with conditional routing.
### Components and Flow
* **Input:** Tokens are labeled as $x_i$ and $x_{i+1}$ at the bottom.
* **Route Block (Light Green):** Each input passes through a "Route" module. Above this module is a small bar chart representing routing weights.
* **Token $x_i$:** Assigned a weight $w=0.41$.
* **Token $x_{i+1}$:** Assigned a weight $w=0.65$.
* **Conditional Path (The Router):**
* The router acts as a switch.
* For **$x_i$**, the path through the computational blocks (Normalize, Self-attention, Normalize, MLP) is **faded/greyed out**, indicating this token is "routed around" the blocks. It follows a bypass connection directly to the output.
* For **$x_{i+1}$**, the path through the computational blocks is **fully colored**, indicating this token "uses the block."
* **Computational Blocks:**
* **Normalize (Red/Pink):** Two instances per layer.
* **Self-attention (Yellow):** Positioned after the first normalization.
* **MLP (Purple):** Positioned after the second normalization.
* **Residual Connections and Operations:**
* **$\oplus$ (Addition):** Represents residual skip connections.
* **$\otimes$ (Multiplication):** The output of the MLP is multiplied by the routing weight (e.g., $w=0.65$ for $x_{i+1}$) before being added back to the residual stream.
* **Vertical Progression:** An arrow pointing up labeled "layers" with vertical dots indicates that this structure repeats for subsequent layers.
---
## 2. Routing Decisions Heatmaps (Right Side)
The right side contains three heatmaps comparing how different architectures process sequences across layers.
### Legend (Bottom Right)
* **Purple Square:** "Use block" (Computation is performed).
* **Orange Square:** "Route around block" (Computation is skipped/bypassed).
### Main Heatmap: Mixture-of-Depths
* **Title:** Mixture-of-Depths / Routing Decisions
* **Y-Axis:** Layer (Vertical)
* **X-Axis:** Sequence (Horizontal)
* **Visual Trend:** The map shows a stochastic, "checkerboard-like" pattern of purple and orange.
* **Data Observation:** In any given layer (row), only a subset of the sequence (columns) is processed (purple), while the rest are bypassed (orange). This indicates a fixed compute budget per layer distributed dynamically across the sequence.
### Comparison Heatmap: Vanilla Transformer
* **Title:** Vanilla Transformer
* **Y-Axis:** Layer
* **X-Axis:** Sequence
* **Visual Trend:** The entire heatmap is solid **Purple**.
* **Data Observation:** Every token in the sequence is processed by every block in every layer. There is no skipping.
### Comparison Heatmap: Early-Exit
* **Title:** Early-Exit
* **Y-Axis:** Layer
* **X-Axis:** Sequence
* **Visual Trend:** The bottom portion of the map is solid purple, while the top-right portion contains orange blocks.
* **Data Observation:** Tokens are processed in early layers. As the sequence progresses through deeper layers (moving up the Y-axis), some tokens "exit" early and bypass the remaining computation (turning orange). Unlike MoD, once a token exits, it typically stays exited for the remaining layers.
---
## 3. Summary of Textual Labels
| Category | Extracted Text |
| :--- | :--- |
| **Main Titles** | Mixture-of-Depths, Routing Decisions |
| **Sub-Titles** | Vanilla Transformer, Early-Exit |
| **Axis Labels** | Layer, Sequence, layers |
| **Block Labels** | Route, Normalize, Self-attention, MLP |
| **Variables** | $x_i$, $x_{i+1}$, $w=0.41$, $w=0.65$ |
| **Legend** | Use block, Route around block |
| **Symbols** | $\oplus$ (Addition), $\otimes$ (Multiplication), $\vdots$ (Continuation) |