\n
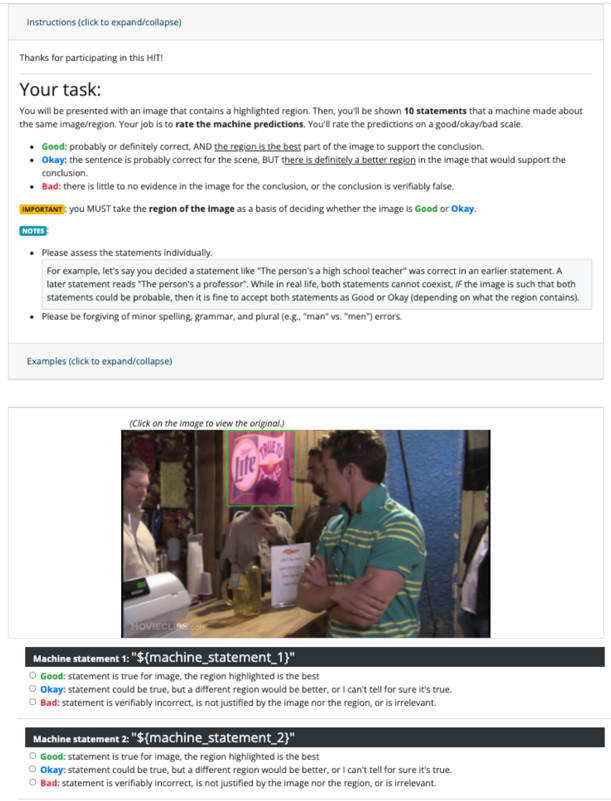
## Screenshot: Mechanical Turk HIT Instructions & Example
### Overview
This is a screenshot of a Mechanical Turk (MTurk) Human Intelligence Task (HIT) interface. The HIT instructs workers to evaluate statements made by a machine about a given image region, rating them as "Good," "Okay," or "Bad" based on how well the region supports the statement. The screenshot includes instructions, notes, examples, and a sample image with associated statements.
### Components/Axes
The screenshot is divided into several sections:
* **Header:** Contains the HIT instructions, thanking the participant and outlining the task.
* **Notes:** Provides additional guidance on assessing statements, including handling contradictory statements and minor errors.
* **Examples:** Shows a sample image and two machine-generated statements with radio button options for rating.
* **Image Region:** A highlighted rectangular region within a photograph of a grocery store shelf.
* **Statement Blocks:** Two blocks, each containing a machine-generated statement and three radio button options for evaluation.
### Detailed Analysis or Content Details
**Header Text (Transcription):**
"Instructions (click to expand/collapse)
Thanks for participating in this HIT!
Your task:
You will be presented with an image that contains a highlighted region. Then, you'll be shown 10 statements that a machine made about the same image/region. Your job is to rate the machine predictions on a good/okay/bad scale.
* **Good:** probably or definitely correct. AND the region is the best part of the image to support the conclusion.
* **Okay:** the sentence is probably correct for the scene, BUT there is definitely a better region in the image that would support the conclusion.
* **Bad:** there is little to no evidence in the image for the conclusion, or the conclusion is verifiably false.
**IMPORTANT:** you MUST take the region of the image as a basis of deciding whether the image is Good or Okay.
**NOTES:**
* Please assess the statements individually.
* For example, let's say you decided a statement like "The person is a high school teacher" was correct in an earlier statement. A later statement reads "The person's a professor." While in real life, both statements cannot coexist, if the image is such that both statements could be probable, then it is fine to accept both statements as Good or Okay (depending on what the region contains).
* Please be forgiving of minor spelling, grammar, and plural (e.g., "man" vs. "men") errors."
**Example Image Description:**
The image shows a section of a grocery store shelf. Visible products include:
* "lite" brand milk cartons (approximately 3 visible)
* "Hormel" brand products (approximately 2 visible)
* "HomeStyle" brand products (approximately 2 visible)
* Other various packaged goods.
The highlighted region is a rectangle encompassing a portion of the shelf with the "lite" milk cartons and some of the "Hormel" products.
**Statement 1 (Transcription):**
"Machine statement 1: ${machine_statement_1}"
* ○ Good: statement is true for image, the region highlighted is the best
* ○ Okay: statement could be true, but a different region would be better, or I can't tell for sure it's true.
* ○ Bad: statement is verifiably incorrect, is not justified by the image nor the region, or is irrelevant.
**Statement 2 (Transcription):**
"Machine statement 2: ${machine_statement_2}"
* ○ Good: statement is true for image, the region highlighted is the best
* ○ Okay: statement could be true, but a different region would be better, or I can't tell for sure it's true.
* ○ Bad: statement is verifiably incorrect, is not justified by the image nor the region, or is irrelevant.
### Key Observations
* The HIT emphasizes evaluating statements *based on the highlighted region* of the image, not the entire image.
* The instructions acknowledge potential ambiguity and the need for forgiveness regarding minor errors.
* The example image is a typical grocery store scene, likely chosen for its common objects and potential for varied statements.
* The statements are placeholders ("${machine\_statement\_1}", "${machine\_statement\_2}"), indicating that the actual statements will be dynamically generated for each HIT instance.
### Interpretation
This HIT is designed to assess the accuracy of a machine vision system's ability to generate statements about image regions. The task requires human workers to act as "ground truth" evaluators, determining whether the machine's statements are supported by the visual evidence within the specified region. The "Good," "Okay," and "Bad" rating scale allows for nuanced evaluation, acknowledging that a statement might be true but not optimally supported by the highlighted region. The instructions highlight the importance of focusing on the region, suggesting that the machine vision system may be generating statements based on specific areas of interest within a larger image. The use of placeholders for the statements indicates a system that can generate a variety of descriptions for different images. This is a common approach in evaluating and improving the performance of image captioning or visual reasoning models. The HIT is a form of weak supervision, where human labels are used to train or refine a machine learning model.