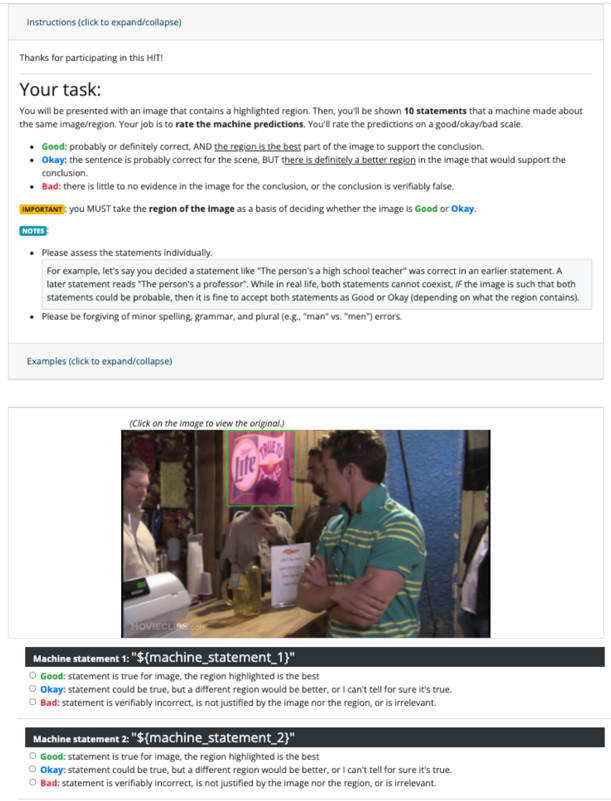
## Screenshot: Amazon Mechanical Turk HIT Task Interface
### Overview
This image depicts a user interface for a Human Intelligence Task (HIT) on Amazon Mechanical Turk. The task involves evaluating machine-generated statements about an image containing a highlighted region. Users must rate each statement as "Good," "Okay," or "Bad" based on its alignment with the image content, particularly the highlighted area.
### Components/Axes
- **Header Section**:
- Title: "Instructions (click to expand/collapse)"
- Text: "Thanks for participating in this HIT!"
- **Task Description**:
- Instructions for rating 10 machine-generated statements about an image with a highlighted region.
- Rating criteria:
- **Good**: Statement is true for the image, and the highlighted region is the best part supporting the conclusion.
- **Okay**: Statement could be true, but a different region would be better, or uncertainty exists.
- **Bad**: Statement is verifiably incorrect, irrelevant, or not justified by the image/region.
- **Important Note**: Users MUST base ratings on the highlighted region.
- **Notes**:
- Assess statements individually.
- Forgive minor spelling/grammar errors.
- **Image Section**:
- A photograph of a social gathering (e.g., a bar) with a highlighted Lite beer logo.
- Text overlay: "(Click on the image to view the original.)"
- **Rating Interface**:
- Two example machine statements labeled `Machine statement 1` and `Machine statement 2`.
- For each statement, three radio buttons for "Good," "Okay," and "Bad" with descriptive criteria.
### Detailed Analysis
- **Image Content**:
- A group of people in a bar setting.
- Highlighted region: A Lite beer logo (pink background with white text).
- Visible objects: Drinks, a cash register, and a menu.
- **Textual Content**:
- Example statements are placeholders (`${machine_statement_1}`, `${machine_statement_2}`).
- Rating criteria emphasize the highlighted region's relevance to the statement's validity.
- **UI Elements**:
- Expand/collapse buttons for instructions and examples.
- Radio buttons for rating options.
### Key Observations
1. The task prioritizes the highlighted region as the basis for evaluation.
2. Statements are assessed individually, even if they conflict with prior conclusions.
3. The interface allows for flexibility in rating (e.g., accepting both "The person’s a high school teacher" and "The person’s a professor" as "Good" or "Okay" if the image supports both interpretations).
4. Minor errors in statements (e.g., "man" vs. "men") are to be overlooked.
### Interpretation
This HIT task is designed to improve machine learning models by crowdsourcing human judgment on the relevance of generated statements to specific image regions. The emphasis on the highlighted region suggests the machine’s focus on key visual elements, and raters must determine whether the statements align with those elements. The example statements illustrate scenarios where contextual ambiguity (e.g., professions) requires raters to weigh visual evidence against textual claims. The task underscores the importance of spatial grounding in image-to-text alignment, as raters must reconcile abstract statements with concrete visual data.