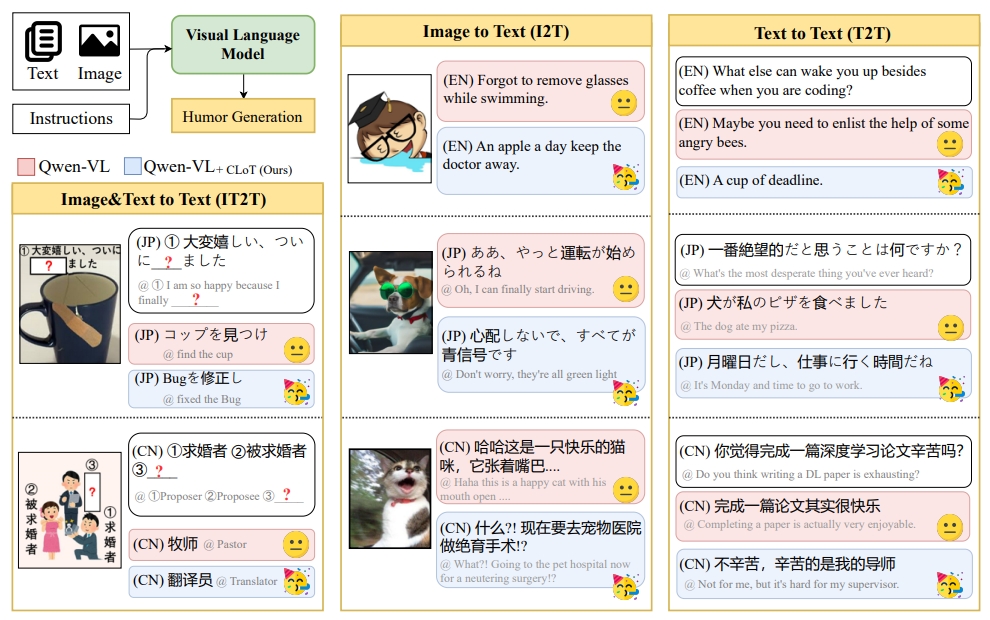
## Diagram: Visual Language Model for Humor Generation
### Overview
The image is a technical diagram illustrating a system architecture and comparative examples for a Visual Language Model (VLM) designed for humor generation. It compares the outputs of a baseline model ("Qwen-VL") with an enhanced model ("Qwen-VL+CLoT (Ours)") across three different input modalities: Image & Text to Text (IT2T), Image to Text (I2T), and Text to Text (T2T). The diagram is organized into three main vertical columns.
### Components/Axes
The diagram is segmented into three primary columns, each with a yellow header:
1. **Left Column:** System Architecture and "Image & Text to Text (IT2T)" examples.
2. **Middle Column:** "Image to Text (I2T)" examples.
3. **Right Column:** "Text to Text (T2T)" examples.
**Legend (Top-Left):**
* A pink rectangle is labeled: `Qwen-VL`
* A blue rectangle is labeled: `Qwen-VL+CLoT (Ours)`
**System Architecture (Top-Left):**
* A box labeled `Text` and an icon labeled `Image` feed into a green box labeled `Visual Language Model`.
* An arrow from the `Visual Language Model` points to a yellow box labeled `Humor Generation`.
* A separate box labeled `Instructions` also feeds into the `Visual Language Model`.
### Detailed Analysis
The diagram presents paired examples for each modality. The top example in each pair (pink background) is from the baseline `Qwen-VL` model, and the bottom example (blue background) is from the enhanced `Qwen-VL+CLoT` model. Each example includes text in a specific language (marked with a language code) and an associated emoji indicating the humor type (a straight-faced 😐 for the baseline, a party popper 🥳 for the enhanced model).
#### Column 1: Image & Text to Text (IT2T)
* **Example 1 (Image: A mug with a spoon inside):**
* **(Pink - Qwen-VL):** `(JP) ① 大変嬉しい、ついに ② ? ました` / `@ I am so happy because I finally ② ?`
* **(Blue - Qwen-VL+CLoT):** `(JP) コップを見つけ` / `@ find the cup`
* **Example 2 (Image: A cartoon of a proposer, proposee, and pastor):**
* **(Pink - Qwen-VL):** `(CN) ①求婚者 ②被求婚者 ③ ?` / `@ ①Proposer ②Proposee ③ ?`
* **(Blue - Qwen-VL+CLoT):** `(CN) 牧师` / `@ Pastor`
* **(Blue - Qwen-VL+CLoT):** `(CN) 翻译员` / `@ Translator`
#### Column 2: Image to Text (I2T)
* **Example 1 (Image: A cartoon of a person swimming with glasses):**
* **(Pink - Qwen-VL):** `(EN) Forgot to remove glasses while swimming.`
* **(Blue - Qwen-VL+CLoT):** `(EN) An apple a day keep the doctor away.`
* **Example 2 (Image: A dog wearing sunglasses driving a car):**
* **(Pink - Qwen-VL):** `(JP) ああ、やっと運転が始われるね` / `@ Oh, I can finally start driving.`
* **(Blue - Qwen-VL+CLoT):** `(JP) 心配しないで、すべてが青色です` / `@ Don't worry, they're all green light`
* **Example 3 (Image: A cat with its mouth open):**
* **(Pink - Qwen-VL):** `(CN) 哈哈这是一只快乐的猫咪,它张着嘴巴...` / `@ Haha this is a happy cat with his mouth open ....`
* **(Blue - Qwen-VL+CLoT):** `(CN) 什么?! 现在要去宠物医院做绝育手术!?` / `@ What?! Going to the pet hospital now for a neutering surgery!?`
#### Column 3: Text to Text (T2T)
* **Example 1 (Prompt):**
* **(Pink - Qwen-VL):** `(EN) What else can wake you up besides coffee when you are coding?`
* **(Blue - Qwen-VL+CLoT):** `(EN) Maybe you need to enlist the help of some angry bees.`
* **(Blue - Qwen-VL+CLoT):** `(EN) A cup of deadline.`
* **Example 2 (Prompt):**
* **(Pink - Qwen-VL):** `(JP) 一番絶望だと思うことは何ですか?` / `@ What's the most desperate thing you've ever heard?`
* **(Blue - Qwen-VL+CLoT):** `(JP) 犬が私のピザを食べました` / `@ The dog ate my pizza.`
* **(Blue - Qwen-VL+CLoT):** `(JP) 月曜日だし、仕事に行く時間だね` / `@ It's Monday and time to go to work.`
* **Example 3 (Prompt):**
* **(Pink - Qwen-VL):** `(CN) 你觉得完成一篇深度学习论文辛苦吗?` / `@ Do you think writing a DL paper is exhausting?`
* **(Blue - Qwen-VL+CLoT):** `(CN) 完成一篇论文其实很快乐` / `@ Completing a paper is actually very enjoyable.`
* **(Blue - Qwen-VL+CLoT):** `(CN) 不辛苦,辛苦的是我的导师` / `@ Not for me, but it's hard for my supervisor`
### Key Observations
1. **Multilingual Output:** The system generates humor in English (EN), Japanese (JP), and Chinese (CN).
2. **Humor Type Contrast:** The baseline model (`Qwen-VL`) often produces literal, descriptive, or incomplete responses (marked with 😐). The enhanced model (`Qwen-VL+CLoT`) generates more creative, pun-based, or situational humor (marked with 🥳).
3. **Input Modalities:** The diagram comprehensively covers three key interaction types for a VLM: combining images and text, generating text from images alone, and generating text from text prompts alone.
4. **Architectural Simplicity:** The core architecture is a straightforward pipeline: Text + Image + Instructions -> Visual Language Model -> Humor Generation.
### Interpretation
This diagram serves as a comparative showcase for the "Qwen-VL+CLoT" model's superior performance in humor generation across multiple languages and input types. The "CLoT" component (likely standing for something like "Chain-of-Thought" or a similar reasoning enhancement) appears to enable the model to move beyond simple description to generate contextually appropriate and witty responses.
The examples demonstrate that the enhanced model can:
* **In IT2T:** Correctly identify and label objects in an image (e.g., "Pastor," "Translator") where the baseline fails.
* **In I2T:** Create humorous captions that involve puns ("green light" for traffic lights) or unexpected, darkly funny twists (neutering surgery) rather than stating the obvious.
* **In T2T:** Provide multiple, creative, and relatable humorous answers to open-ended questions, whereas the baseline gives a single, more conventional response.
The consistent use of emojis (😐 vs. 🥳) visually reinforces the claimed improvement in humor quality. The diagram effectively argues that adding the CLoT mechanism to the base Qwen-VL model significantly boosts its ability to understand context and generate engaging, human-like humor.