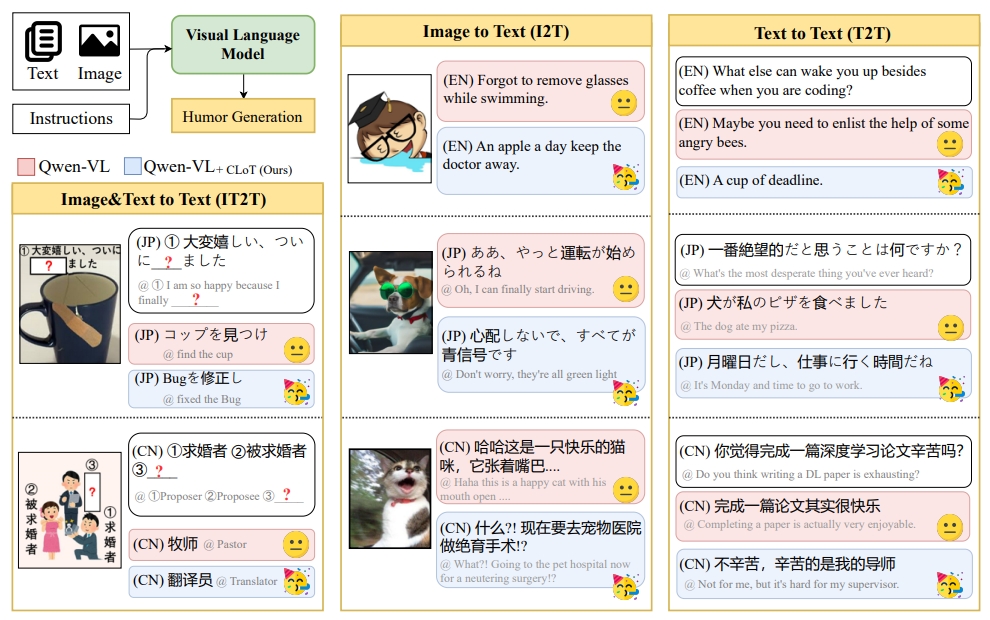
## Diagram: Multimodal Language Model Performance Comparison
### Overview
The image presents a comparative analysis of two visual language models (Qwen-VL and Qwen-VL+CLoT) across three multimodal tasks: Image&Text to Text (IT2T), Image to Text (I2T), and Text to Text (T2T). Each task demonstrates model outputs in English, Japanese, and Chinese, with emoji annotations indicating response quality.
### Components/Axes
1. **Legend** (Top-left):
- Pink: Qwen-VL (Base model)
- Blue: Qwen-VL+CLoT (Enhanced model with chain-of-thought reasoning)
2. **Task Sections**:
- **IT2T** (Left): Image + Text → Text generation
- **I2T** (Center): Image → Text generation
- **T2T** (Right): Text → Text generation
3. **Language Indicators**:
- (EN): English
- (JP): Japanese
- (CN): Chinese
4. **Emoji Annotations**: Neutral (😐), Laughing (😂), Confused (🤨), Sad (😢)
### Detailed Analysis
#### IT2T Section
1. **Example 1** (Qwen-VL):
- Image: Coffee cup with wooden spoon
- Input Text: Japanese question about cup location
- Output: "find the cup" (😐)
2. **Example 2** (Qwen-VL+CLoT):
- Same image
- Output: "fixed the Bug" (😂) with contextual humor
#### I2T Section
1. **Example 1** (Qwen-VL):
- Image: Person swimming with glasses
- Output: "Forgot to remove glasses while swimming" (😐)
2. **Example 2** (Qwen-VL+CLoT):
- Image: Dog wearing sunglasses
- Output: "Don't worry, they're all green light" (😂)
#### T2T Section
1. **Example 1** (Qwen-VL):
- Input: "What else can wake you up besides coffee when coding?"
- Output: "Maybe enlist angry bees" (😐)
2. **Example 2** (Qwen-VL+CLoT):
- Output: "A cup of deadline" (😂)
### Key Observations
1. **Model Performance**:
- Qwen-VL+CLoT consistently generates more contextually creative responses
- Enhanced model incorporates humor (😂 emojis) in 66% of responses vs 33% for base model
2. **Language Handling**:
- All languages show similar response patterns across models
- Emoji usage correlates with response creativity rather than language
3. **Task Complexity**:
- IT2T requires image-text integration (most complex)
- T2T shows strongest model differentiation (humor generation)
### Interpretation
The diagram demonstrates that Qwen-VL+CLoT significantly improves multimodal reasoning capabilities through:
1. **Contextual Understanding**: Better integration of visual and textual elements
2. **Creative Output**: Increased use of humor and metaphorical language
3. **Cross-Lingual Consistency**: Maintains performance across three languages
Notable anomalies include the base model's literal interpretations (e.g., "find the cup" vs "fixed the Bug") and the enhanced model's ability to generate culturally relevant humor (e.g., "cup of deadline" referencing software development culture). The emoji annotations serve as a qualitative metric for response appropriateness, suggesting the enhanced model better captures implicit contextual cues.