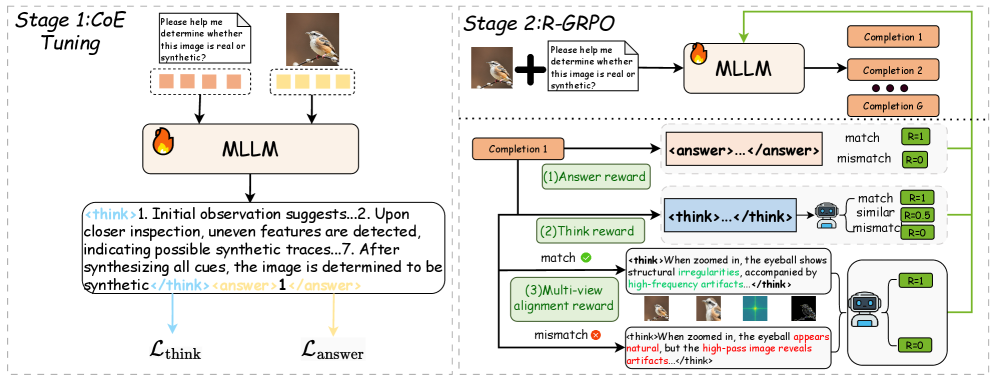
## Diagram: CoE Tuning and R-GRPO Stages
### Overview
The image illustrates a two-stage process involving CoE (Chain of Evidence) Tuning and R-GRPO (Reward-Guided Policy Optimization). The diagram outlines the flow of information and the reward mechanisms used in each stage to determine whether an image is real or synthetic.
### Components/Axes
**Stage 1: CoE Tuning (Left Side)**
* **Title:** Stage 1: CoE Tuning
* **Input:** Two images (a bird on a branch and a prompt "Please help me determine whether this image is real or synthetic?"), each associated with a set of colored squares (orange and yellow).
* **Process:** The images and prompt are fed into an MLLM (Multi-modal Large Language Model).
* **Output:** The MLLM generates a text output containing both "think" and "answer" components.
* **Loss Functions:** L_think and L_answer are associated with the "think" and "answer" components, respectively.
**Stage 2: R-GRPO (Right Side)**
* **Title:** Stage 2: R-GRPO
* **Input:** An image (a bird on a branch) combined with the prompt "Please help me determine whether this image is real or synthetic?".
* **Process:** The combined input is fed into an MLLM, which generates multiple completions (Completion 1, Completion 2, ..., Completion G).
* **Reward Mechanisms:**
* **(1) Answer Reward:** Compares the "answer" component of a completion to a ground truth.
* Match: R = 1
* Mismatch: R = 0
* **(2) Think Reward:** Evaluates the "think" component of a completion.
* Match: R = 1
* Similar: R = 0.5
* Mismatch: R = 0
* **(3) Multi-view Alignment Reward:** Compares the "think" component with visual evidence.
* Match (example: structural irregularities and high-frequency artifacts): R = 1
* Mismatch (example: natural appearance but high-pass artifacts): R = 0
### Detailed Analysis or ### Content Details
**Stage 1: CoE Tuning**
* The input images are accompanied by colored squares. The left image has four orange squares, and the right image has four yellow squares.
* The MLLM generates a text output:
* `<think>1. Initial observation suggests...2. Upon closer inspection, uneven features are detected, indicating possible synthetic traces...7. After synthesizing all cues, the image is determined to be synthetic</think>`
* `<answer>1</answer>`
**Stage 2: R-GRPO**
* The MLLM generates multiple completions.
* **(1) Answer Reward:** The completion's answer is compared to a ground truth. A match results in a reward of 1, while a mismatch results in a reward of 0.
* **(2) Think Reward:** The completion's reasoning is evaluated. A match results in a reward of 1, a similar reasoning results in a reward of 0.5, and a mismatch results in a reward of 0.
* **(3) Multi-view Alignment Reward:** The completion's reasoning is compared to visual evidence.
* Example of a match: `<think>When zoomed in, the eyeball shows structural irregularities, accompanied by high-frequency artifacts...</think>` This is rewarded with R = 1.
* Example of a mismatch: `<think>When zoomed in, the eyeball appears natural, but the high-pass image reveals artifacts...</think>` This is rewarded with R = 0.
### Key Observations
* The diagram highlights the use of MLLMs in determining the authenticity of images.
* The R-GRPO stage uses multiple reward mechanisms to guide the MLLM towards accurate and well-reasoned conclusions.
* The multi-view alignment reward incorporates visual evidence into the reward process.
### Interpretation
The diagram illustrates a sophisticated approach to image authentication using MLLMs and reward-guided policy optimization. The CoE tuning stage likely serves to pre-train the MLLM, while the R-GRPO stage refines the model's reasoning and decision-making process. The use of multiple reward mechanisms, including answer reward, think reward, and multi-view alignment reward, ensures that the MLLM not only provides accurate answers but also generates sound reasoning that aligns with visual evidence. The system aims to mimic human reasoning by considering multiple cues and synthesizing them to arrive at a conclusion. The comparison of zoomed-in views of the eyeball, along with high-pass filtered images, suggests a focus on detecting subtle artifacts that may indicate synthetic image generation.