\n
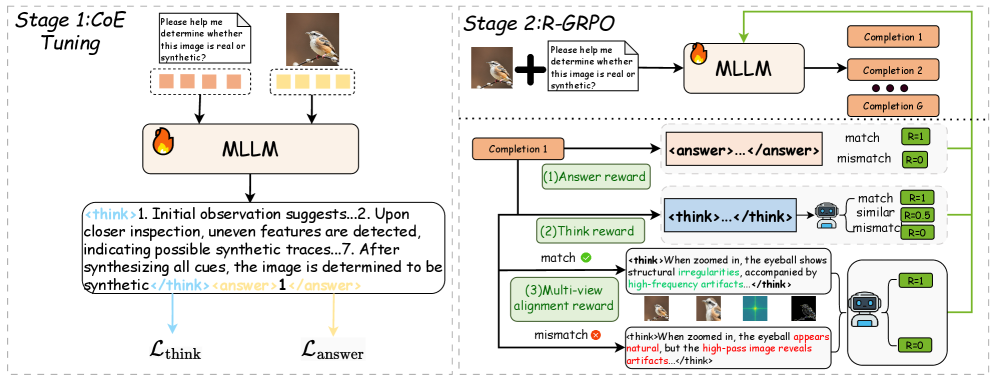
## Diagram: Two-Stage Real/Synthetic Image Determination Pipeline
### Overview
The image depicts a two-stage pipeline for determining whether an image is real or synthetic. The pipeline utilizes a Multi-modal Large Language Model (MLLM) and incorporates a reward system based on both answer accuracy and reasoning quality. The stages are labeled "Stage 1: CoE Tuning" and "Stage 2: R-GRPO".
### Components/Axes
The diagram consists of two main stages, each with several components. Key elements include:
* **MLLM:** Present in both stages, acting as the core processing unit.
* **Input Images:** Represented by a series of orange rectangles in Stage 1 and individual images in Stage 2.
* **Question Prompt:** A text box within each stage asking "Please help me determine whether this image is real or synthetic?".
* **Completion Outputs:** In Stage 2, a series of "Completion" boxes (Completion 1 to Completion G) represent potential answers.
* **Reward Signals:** Represented by green "match" and red "mismatch" signals.
* **Reasoning Blocks:** Text enclosed in `` tags, representing the MLLM's reasoning process.
* **Answer Blocks:** Text enclosed in `<answer>...</answer>` tags, representing the MLLM's final answer.
* **Loss Functions:** Labeled as `L_think` and `L_answer` at the bottom of Stage 1.
* **Legend:** Located in the top-right corner, associating colors with reward outcomes: R-1 (match), R-0 (mismatch), R-0.5 (similar).
### Detailed Analysis or Content Details
**Stage 1: CoE Tuning**
* Input: A sequence of 8 orange rectangles representing images.
* Question: "Please help me determine whether this image is real or synthetic?".
* MLLM processes the input and generates reasoning and an answer.
* Reasoning: ``.
* Answer: `<answer>1</answer>`.
* Outputs: Two loss functions, `L_think` and `L_answer`.
**Stage 2: R-GRPO**
* Input: A single image.
* Question: "Please help me determine whether this image is real or synthetic?".
* MLLM processes the input and generates reasoning and an answer.
* Completion Outputs: A series of "Completion" boxes (Completion 1 to Completion G) are shown.
* **(1) Answer Reward:**
* Input: Completion 1.
* Reasoning: ``.
* Answer: `<answer>...</answer>`.
* Reward: Green "match" signal, labeled "R-1".
* **(2) Think Reward:**
* Input: A green "match" signal.
* Reasoning: ``.
* Reward: Green "match" signal, labeled "R-1".
* **(3) Multi-view alignment reward:**
* Input: A red "mismatch" signal.
* Reasoning: ``.
* Reward: Red "mismatch" signal, labeled "R-0".
**Legend:**
* Green: "match" - R-1, R-0.5
* Red: "mismatch" - R-0
### Key Observations
* The pipeline uses a two-stage approach, starting with CoE Tuning and refining with R-GRPO.
* The R-GRPO stage incorporates multiple reward signals based on both answer accuracy and the quality of the reasoning process.
* The reasoning blocks provide insight into the MLLM's decision-making process.
* The reward signals are color-coded (green for match, red for mismatch) and associated with numerical values (R-1, R-0, R-0.5).
* The diagram highlights the importance of both high-level reasoning and low-level image analysis (zooming in on details).
### Interpretation
The diagram illustrates a sophisticated approach to detecting synthetic images. The two-stage pipeline aims to improve the reliability of the detection process by combining initial coarse-grained analysis (Stage 1) with more refined, multi-faceted evaluation (Stage 2). The use of reward signals for both answer accuracy and reasoning quality suggests a focus on not only *what* the MLLM predicts but also *why* it makes that prediction. The inclusion of detailed reasoning examples (within the `<think>` tags) demonstrates the importance of explainability in this context. The different reward values (R-1, R-0, R-0.5) suggest a graded reward system, allowing for partial credit for reasoning that is partially correct or insightful. The example of the eyeball analysis highlights the use of fine-grained image features to detect subtle artifacts that might indicate synthetic origin. This pipeline is likely designed to address the challenges of increasingly realistic synthetic images, where traditional detection methods may fail.