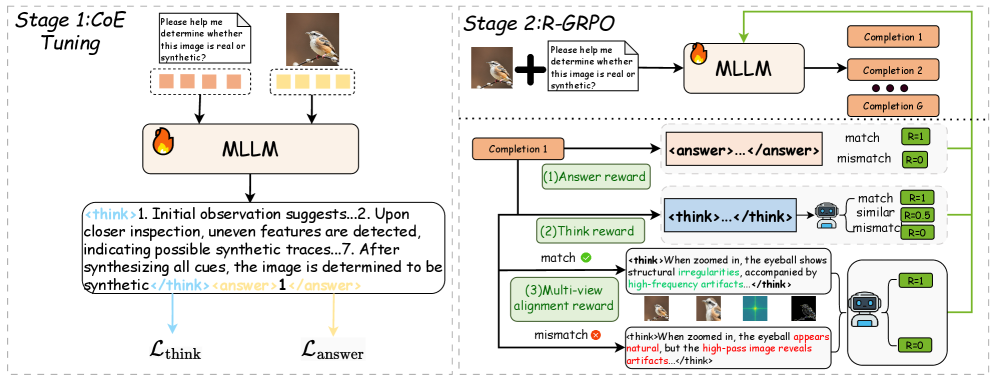
# Technical Document Extraction: Image Analysis
## Overview
The image depicts a **two-stage computational framework** for image authenticity verification using a **Multi-Layer Language Model (MLLM)**. The process involves **coefficient tuning** and **reward-guided reasoning** (R-GRPO) to distinguish real vs. synthetic images.
---
### Stage 1: CoE Tuning
**Purpose**: Initial training of the MLLM to detect synthetic artifacts.
#### Components:
1. **Input Prompt**:
- Text: `"Please help me determine whether this image is real or synthetic?"`
- Example images:
- A bird on a branch (real)
- A flame icon (synthetic)
2. **MLLM Processing**:
- **Think Block**:
- Reasoning steps:
1. Initial observation suggests...
2. Upon closer inspection, uneven features are detected...
7. After synthesizing all cues, the image is determined to be synthetic.
- **Output**:
- Answer: `1` (synthetic)
3. **Loss Functions**:
- `L_think`: Optimizes reasoning coherence.
- `L_answer`: Penalizes incorrect synthetic/real classification.
#### Flow:
```mermaid
graph LR
A[Input Prompt] --> B[MLLM]
B --> C[Think Block]
C --> D[Answer]
```
---
### Stage 2: R-GRPO (Reward-Guided Reasoning)
**Purpose**: Refine the MLLM using multi-view alignment and completion rewards.
#### Components:
1. **Input Prompt**:
- Text: `"Please help me determine whether this image is real or synthetic?"`
- Example image: Bird with zoom-ins showing:
- Natural eye details
- High-frequency artifacts (e.g., "high-pass image reveals artifacts")
2. **MLLM Processing**:
- **Completion Steps** (1 to G):
- Each completion generates a reasoning trace (e.g., ``).
- **Reward Evaluation**:
- **Answer Reward**:
- `R=1` if completion matches ground truth (`<answer>...</answer>`).
- `R=0` if mismatch.
- **Think Reward**:
- `R=1` for coherent reasoning (e.g., "When zoomed in, the eyeball shows structural irregularities...").
- `R=0` for mismatched logic.
- **Multi-View Alignment Reward**:
- `R=1` for consistency across zoom levels.
- `R=0` for discrepancies (e.g., "eye appears natural" vs. "artifacts in high-pass image").
3. **Example Flow**:
- Bird image → Zoom-ins reveal artifacts → Mismatch → `R=0`.
#### Flow:
```mermaid
graph LR
E[Input Prompt] --> F[MLLM]
F --> G[Completion 1]
G --> H[Answer Reward (R=1)]
G --> I[Think Reward (R=1)]
G --> J[Multi-View Alignment Reward (R=0)]
```
---
### Key Trends & Data Points
1. **Synthetic Detection**:
- The MLLM identifies uneven features (e.g., flame icon) as synthetic.
- Zoom-ins reveal high-frequency artifacts in synthetic images.
2. **Reward System**:
- **Binary Rewards**: `R=1` (match), `R=0` (mismatch).
- **Multi-View Alignment**: Ensures consistency across zoom levels.
3. **Loss Optimization**:
- `L_think` and `L_answer` drive the MLLM to refine reasoning and classification accuracy.
---
### Spatial Grounding & Component Isolation
- **Stage 1 (Left)**: Focuses on initial tuning with single-image prompts.
- **Stage 2 (Right)**: Expands to multi-view reasoning with reward signals.
- **Legend**: Not explicitly present; rewards (`R=1`, `R=0`) are implicitly tied to color-coded blocks (green for match, red for mismatch).
---
### Critical Observations
- **Flowchart Logic**:
1. Input prompts are processed by the MLLM.
2. Reasoning traces (``) guide synthetic detection.
3. Rewards (`R=1/R=0`) refine the model’s decision-making.
- **Example Artifacts**:
- Flame icon (synthetic) vs. bird (real).
- High-pass image artifacts in zoomed bird images.
---
### Final Notes
- **Language**: All text is in English.
- **No Data Tables**: The diagram uses flowcharts and textual annotations instead of numerical tables.
- **Trend Verification**:
- Synthetic images show uneven features and artifacts.
- Reward signals (`R=1/R=0`) correlate with match/mismatch outcomes.